














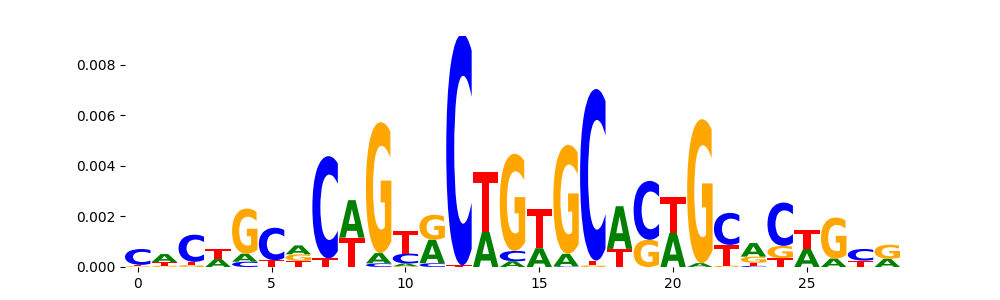




























The image below should look closely like a Tn5 or DNase bias enzyme motif.

The val loss (validation loss) will decrease and saturate after a few epochs.

Counts Metrics: The pearsonr in non-peaks should be greater than 0 (higher the better). The pearsonr in peaks should be greater than -0.3 (otherwise the bias model could potentially be capturing AT bias). MSE (Mean Squared Error) will be high in peaks.
Profile Metrics: Median JSD (Jensen Shannon Divergence between observed and predicted) lower the better. Median norm JSD is median of the min-max normalized JSD where min JSD is the worst case JSD i.e JSD of observed with uniform profile and max JSD is the best case JSD i.e 0. Median norm JSD is higher the better. Both JSD and median norm JSD are sensitive to read-depth. Higher read-depth results in better metrics.
What to do if your pearsonr in peaks is less than -0.3? In the range of -0.3 to -0.5 please be wary of your chrombpnet_wo_bias.h5 (that wil potentially be trained with this bias model) TFModisco showing lots of GC rich motifs (> 3 in the top-10). If this is not the case you can continue using the chrombpnet_wo_bias.h5. If you end up seeing a lot of GC rich motifs it is likely that bias model has learnt a different GC distribution than your GC-content in peaks. You might benefit from increasing the bias_threshold_factor argument input to the chrombpnet bias pipeline or chrombpnet bias train command used in training the bias model and retrain a new bias model. For more intuition about this argument refer to the FAQ section in wiki. If the value is less than -0.5 the chrombpnet training will automatically throw an error.
| nonpeaks.pearsonr | nonpeaks.mse | peaks.pearsonr | peaks.mse | |
|---|---|---|---|---|
| counts_metrics | 0.46 | 0.72 | 0.38 | 12.95 |
| nonpeaks.median_jsd | nonpeaks.median_norm_jsd | peaks.median_jsd | peaks.median_norm_jsd | |
|---|---|---|---|---|
| profile_metrics | 0.77 | 0.05 | 0.54 | 0.24 |
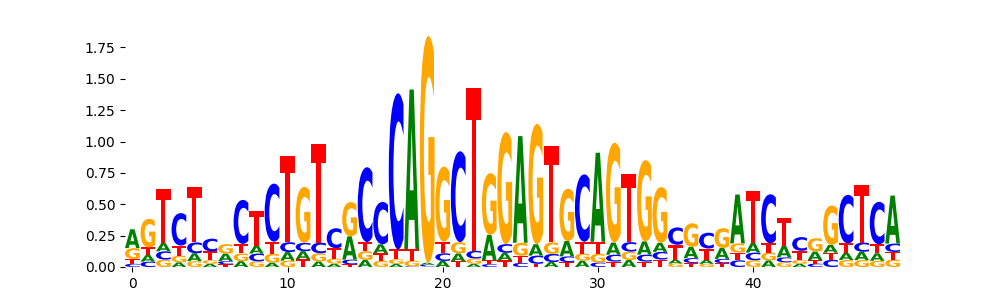
TFModisco motifs generated from profile contribution scores of the bias model. cwm_fwd, cwm_rev are the forward and reverse complemented consolidated motifs from contribution scores in subset of random peaks. These CWM motifs should be free from any Transcription Factor (TF) motifs and should contain either only bias motifs or random repeats. For each of these motifs, we use TOMTOM to find the top-3 closest matches (match_0, match_1, match_2) from a database consisting of both MEME TF motifs and heterogenous enzyme bias motifs that we have repeatedly seen in our datasets. The qvals (qval0,qval1,qval2) should be high (> 0.0001) if the closest hit is a TF motif (i.e indicating that the closest match is not the correct match) - this is also generally verifiable by eye as the closest match will look nothing like the CWMs. The qvals should be low if the closest hit is enzyme bias motif and generally verifiable that the top match looks like the CWM. The first 3-5 motifs in the list below should look like enzyme bias motif.
What to do if you find an obvious TF motif in the list?
Do not use this bias model as it will regress the contribution of the TF motifs (along with bias motifs) from the chrombpnet_nobias.h5. Reduce the bias_threshold_factor argument input to the chrombpnet bias pipeline or chrombpnet bias train command used in training the bias model and retrain a new bias model. For more intuition about this argument refer to the FAQ section in wiki.
What to do if you are unsure if a given CWM motif is resembling the match_0 logo for example?
Get marginal footprint on the match_0 motif logo (using the command chrombpnet footprints and make sure that the bias models footprint is closer to that of controls with no motif inserted - for examples look at FAQ )
| pattern | NumSeqs | cwm_fwd | cwm_rev | match0 | qval0 | match0_logo | match1 | qval1 | match1_logo | match2 | qval2 | match2_logo |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| pos__0 | 7894 | |
|
TN5_1 | 1.478630e-08 | |
TN5_2 | 1.478630e-08 | |
TN5_7 | 0.000776 | |
| pos__1 | 4612 | |
|
TN5_4 | 2.535520e-02 | |
TN5_5 | 2.535520e-02 | |
TN5_8 | 0.058796 | |
| pos__2 | 4335 | |
|
TN5_1 | 8.336010e-04 | |
TN5_2 | 8.336010e-04 | |
TN5_3 | 0.013308 | |
| pos__3 | 2920 | |
|
TN5_3 | 8.605180e-02 | |
TN5_4 | 8.605180e-02 | |
TN5_5 | 0.086052 | |
| pos__4 | 2688 | |
|
TN5_2 | 4.962960e-15 | |
TN5_4 | 1.418760e-04 | |
TN5_5 | 0.000142 | |
| pos__5 | 2037 | |
|
TN5_3 | 2.217820e-13 | |
TN5_4 | 6.979180e-05 | |
TN5_5 | 0.000070 | |
| pos__6 | 1708 | |
|
TN5_7 | 2.699110e-02 | |
TN5_1 | 3.290570e-02 | |
TN5_3 | 0.048914 | |
| pos__7 | 825 | |
|
TN5_3 | 1.517330e-06 | |
TN5_1 | 2.812930e-04 | |
TN5_2 | 0.001245 | |
| pos__8 | 607 | |
|
TN5_6 | 1.248280e-14 | |
TEAD1_HUMAN.H11MO.0.A | 7.906530e-01 | |
TEAD2_MA1121.1 | 0.925321 | |
| pos__9 | 497 | |
|
TN5_7 | 4.404630e-03 | |
TN5_4 | 4.404630e-03 | |
TN5_5 | 0.004405 | |
| pos__10 | 312 | |
|
TN5_7 | 4.705050e-04 | |
TN5_4 | 4.705050e-04 | |
TN5_5 | 0.000471 | |
| pos__11 | 311 | |
|
PRDM6_HUMAN.H11MO.0.C | 8.799420e-02 | |
ZNF384_MA1125.1 | 8.799420e-02 | |
STAT1_MOUSE.H11MO.0.A | 0.190310 | |
| pos__12 | 162 | |
|
TN5_4 | 4.367170e-01 | |
TN5_5 | 4.367170e-01 | |
TBX20_TBX_5 | 0.436717 | |
| pos__13 | 71 | |
|
TN5_4 | 2.139860e-03 | |
TN5_5 | 2.139860e-03 | |
TN5_3 | 0.124497 | |
| pos__14 | 37 | |
|
TN5_8 | 2.458220e-05 | |
GCR_MOUSE.H11MO.0.A | 6.166410e-01 | |
ESR1_MOUSE.H11MO.0.A | 0.616641 | |
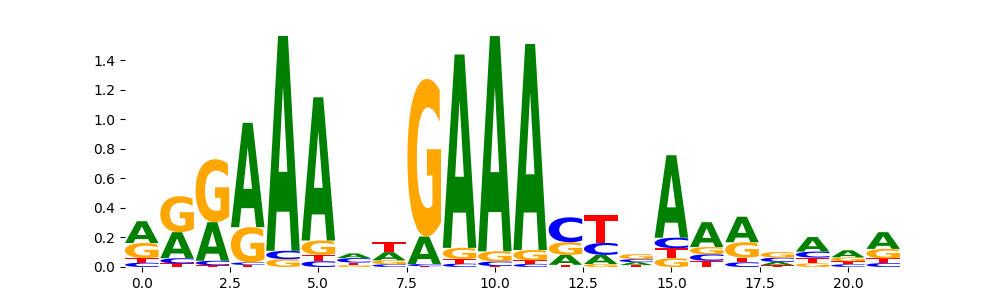
TFModisco motifs generated from counts contribution scores of the bias model. cwm_fwd, cwm_rev are the forward and reverse complemented consolidated motifs from contribution scores in subset of random peaks. These motifs should be free from any Transcription Factor (TF) motifs and should contain motifs either weakly related to bias motifs or random repeats. For each of these motifs, we use TOMTOM to find the top-3 closest matches (match_0, match_1, match_2) from a database consisting of both MEME TF motifs and heterogenous enzyme bias motifs that we have repeatedly seen in our datasets. The qvals should be high (> 0.0001) if the closest hit is a TF motif (i.e indicating that the closest match is not the correct match, this is also generally verifiable by eye and making sure the closest match looks nothing like the CWMs).
What to do if you find an obvious TF motif in the list?
Do not use this bias model as it will regress the contribution of the TF motifs (along with bias motifs) from the chrombpnet_nobias.h5. Reduce the bias_threshold_factor argument input to the chrombpnet bias pipeline or chrombpnet bias train command used in training the bias model and retrain a new bias model. For more intuition about this argument refer to the FAQ section in wiki.
What to do if you are unsure if a given CWM motif is resembling the match_0 logo for example?
Get marginal footprint on the match_0 motif logo (using the command chrombpnet footprints and make sure that the bias models footprint is closer to that of controls with no motif inserted - for examples look at FAQ )
| pattern | NumSeqs | cwm_fwd | cwm_rev | match0 | qval0 | match0_logo | match1 | qval1 | match1_logo | match2 | qval2 | match2_logo |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| pos__0 | 5956 | 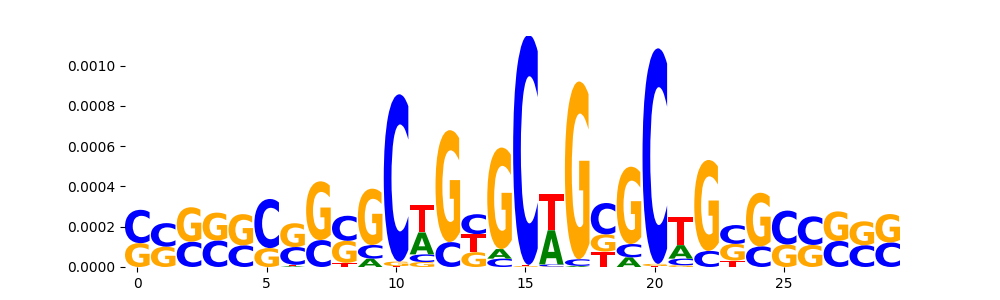 |
 |
TN5_2 | 6.989740e-03 |  |
TN5_7 | 0.006990 |  |
TN5_1 | 0.006990 |  |
| pos__1 | 4683 |  |
 |
TN5_2 | 9.534780e-06 | |
TN5_4 | 0.085649 |  |
TN5_5 | 0.085649 |  |
| pos__2 | 4175 |  |
 |
P53_MOUSE.H11MO.0.A | 1.631170e-01 |  |
SP2_HUMAN.H11MO.0.A | 0.163117 |  |
SP2_MOUSE.H11MO.0.B | 0.163117 |  |
| pos__3 | 2504 |  |
 |
TN5_7 | 1.566380e-01 | |
ZN667_HUMAN.H11MO.0.C | 1.000000 |  |
ZFX_MOUSE.H11MO.0.B | 1.000000 |  |
| pos__4 | 2183 |  |
 |
KLF6_HUMAN.H11MO.0.A | 2.479140e-02 |  |
KLF6_MOUSE.H11MO.0.B | 0.024791 |  |
KLF3_HUMAN.H11MO.0.B | 0.024791 |  |
| pos__5 | 1786 |  |
 |
TN5_6 | 9.671810e-24 |  |
TEAD1_HUMAN.H11MO.0.A | 0.679506 |  |
ZSC31_HUMAN.H11MO.0.C | 0.679506 |  |
| pos__6 | 983 | 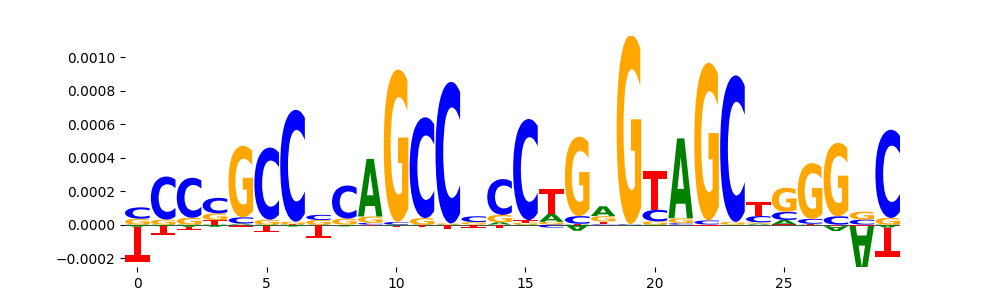 |
 |
ZN770_HUMAN.H11MO.0.C | 2.132670e-01 |  |
TFAP2C_MA0814.1 | 0.512485 |  |
TFAP2C_TFAP_2 | 0.512485 |  |
| pos__7 | 912 |  |
 |
TN5_6 | 1.000000e+00 | |
ZBT18_HUMAN.H11MO.0.C | 1.000000 |  |
TBX20_MOUSE.H11MO.0.C | 1.000000 |  |
| pos__8 | 824 |  |
 |
TN5_2 | 1.919160e-02 | |
TN5_8 | 0.019192 |  |
TN5_4 | 0.063285 | |
| pos__9 | 747 |  |
 |
SP5_MOUSE.H11MO.0.C | 5.148890e-04 |  |
RXRA_HUMAN.H11MO.0.A | 0.000651 |  |
MAZ_HUMAN.H11MO.0.A | 0.001359 |  |
| pos__10 | 671 |  |
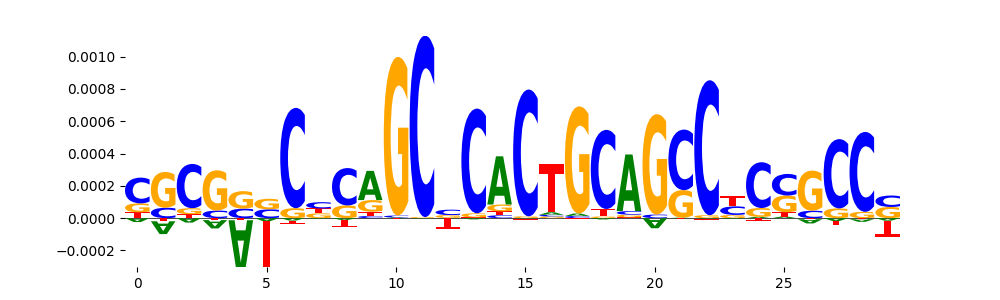 |
RARG_HUMAN.H11MO.0.B | 1.000000e+00 |  |
RARG_MOUSE.H11MO.0.C | 1.000000 |  |
ASCL1_MOUSE.H11MO.0.A | 1.000000 |  |
| pos__11 | 594 |  |
 |
FOS_HUMAN.H11MO.0.A | 4.974250e-01 |  |
FOSL1_MA0477.1 | 0.497425 |  |
MGA_MA0801.1 | 0.497425 |  |
| pos__12 | 467 |  |
 |
HTF4_HUMAN.H11MO.0.A | 2.887860e-01 |  |
ITF2_HUMAN.H11MO.0.C | 0.288786 |  |
ETV6_ETS_1 | 0.513730 |  |
| pos__13 | 323 |  |
 |
NR1D2_MOUSE.H11MO.0.A | 1.000000e+00 |  |
ERR1_HUMAN.H11MO.0.A | 1.000000 |  |
EGR1_HUMAN.H11MO.0.A | 1.000000 |  |
| pos__14 | 297 | 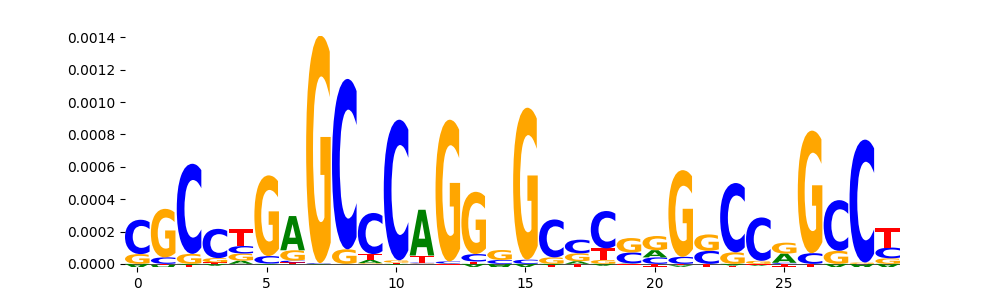 |
 |
DNASE_5 | 1.014020e-06 |  |
Nr5a2_MA0505.1 | 0.024221 |  |
RXRA_MOUSE.H11MO.0.A | 0.024221 |  |
| pos__15 | 296 |  |
 |
BRAC_MOUSE.H11MO.0.B | 1.000000e+00 | 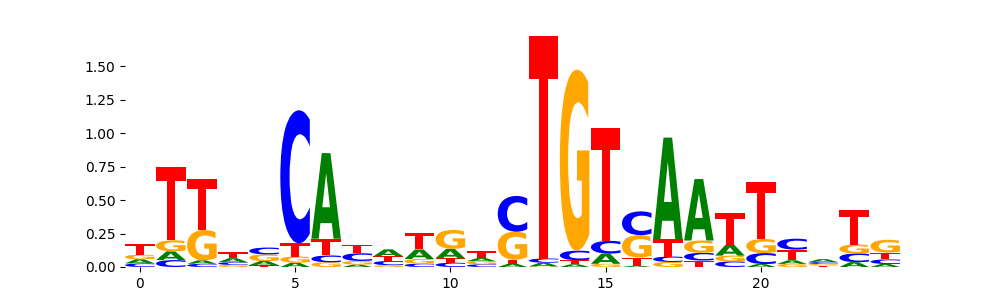 |
NaN | NaN | NaN | NaN | ||
| pos__16 | 278 |  |
 |
RXRA_MOUSE.H11MO.0.A | 6.668660e-01 | |
RARA_HUMAN.H11MO.0.A | 0.666866 |  |
RARA_MOUSE.H11MO.0.A | 0.666866 |  |
| pos__17 | 232 |  |
 |
TN5_4 | 1.872510e-01 | |
TN5_5 | 0.187251 | |
ZBT17_HUMAN.H11MO.0.A | 0.187251 |  |
| pos__18 | 182 |  |
 |
TBX1_TBX_1 | 1.000000e+00 |  |
MGA_MA0801.1 | 1.000000 | |
MGA_TBX_1 | 1.000000 |  |
| pos__19 | 140 |  |
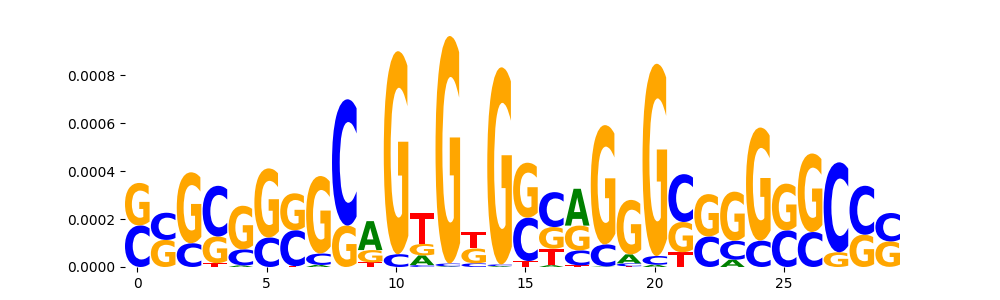 |
ZN768_HUMAN.H11MO.0.C | 1.688630e-01 |  |
NR1D1_HUMAN.H11MO.0.B | 0.168863 | 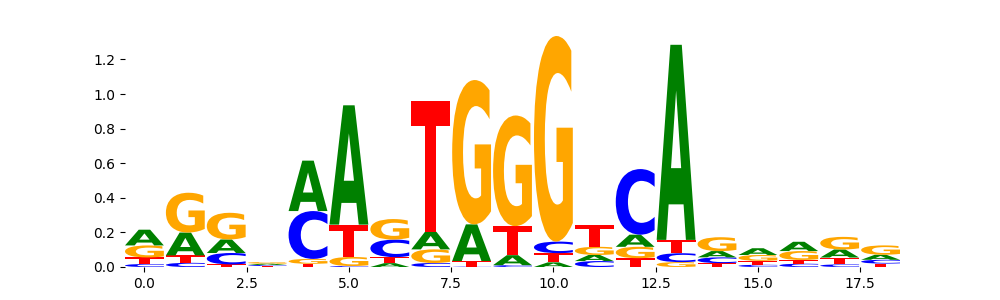 |
NR1D1_MOUSE.H11MO.0.A | 0.168863 |  |
| pos__20 | 95 |  |
 |
PRDM6_HUMAN.H11MO.0.C | 6.244030e-02 |  |
ZNF384_MA1125.1 | 0.062440 |  |
STAT1_MOUSE.H11MO.0.A | 0.062440 |  |
| pos__21 | 73 |  |
 |
ZN322_MOUSE.H11MO.0.B | 7.761270e-01 |  |
DMRTB_MOUSE.H11MO.0.C | 0.776127 |  |
ZN322_HUMAN.H11MO.0.B | 0.776127 |  |
| pos__22 | 52 |  |
 |
PRDM6_HUMAN.H11MO.0.C | 1.074740e-01 | |
ZNF384_MA1125.1 | 0.107474 | |
STAT1_MOUSE.H11MO.0.A | 0.107474 | |
| pos__23 | 44 |  |
 |
SMAD3_HUMAN.H11MO.0.B | 4.988850e-02 | 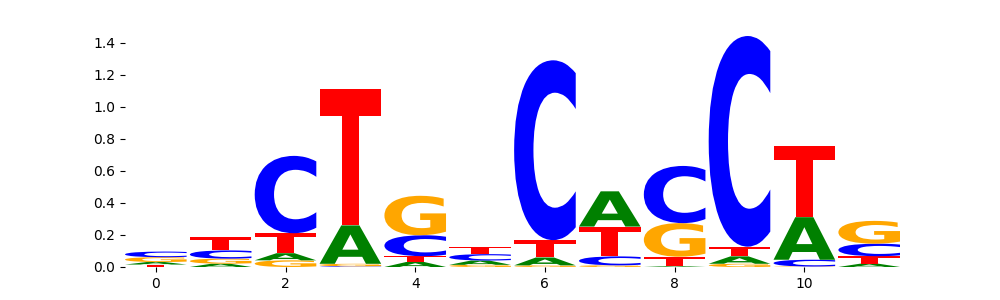 |
SMAD3_MOUSE.H11MO.0.B | 0.049889 |  |
VDR_MA0693.2 | 1.000000 |  |
| pos__24 | 34 |  |
 |
THA_HUMAN.H11MO.0.C | 1.421750e-01 |  |
DNASE_3 | 0.370554 |  |
ZN667_HUMAN.H11MO.0.C | 1.000000 | |
| pos__25 | 31 |  |
 |
CTCFL_HUMAN.H11MO.0.A | 3.983110e-01 |  |
CTCFL_MOUSE.H11MO.0.A | 0.398311 |  |
CTCFL_MA1102.1 | 0.398311 |  |
| pos__26 | 28 |  |
 |
NR1H3_HUMAN.H11MO.0.B | 1.000000e+00 |  |
ZKSC1_HUMAN.H11MO.0.B | 1.000000 |  |
ZKSC1_MOUSE.H11MO.0.A | 1.000000 |  |
| pos__27 | 27 |  |
 |
ZN770_HUMAN.H11MO.0.C | 1.263100e-01 | |
IKZF1_HUMAN.H11MO.0.C | 0.650863 |  |
IKZF1_MOUSE.H11MO.0.C | 0.650863 |  |
| pos__28 | 23 |  |
 |
PRDM6_HUMAN.H11MO.0.C | 1.434860e-01 | |
ZNF384_MA1125.1 | 0.143486 | |
STAT1_MOUSE.H11MO.0.A | 0.206448 | |