BPNet tf-Modisco report¶
url_dir = "http://mitra.stanford.edu/kundaje/avsec/chipnexus/oct-sox-nanog-klf/models/n_dil_layers=9/modisco/valid/new-hparams/plots/"
modisco_dir = "/users/avsec/workspace/basepair/data/processed/chipnexus/exp/models/oct-sox-nanog-klf/models/n_dil_layers=9/modisco/valid/new-hparams"
# Parameters
url_dir = "http://mitra.stanford.edu/kundaje/avsec/chipnexus/oct-sox-nanog-klf/models/n_dil_layers=9/modisco/clustered/weighted/1/plots/"
modisco_dir = "1"
from basepair.modisco import ModiscoResult
from basepair.config import get_data_dir
from basepair.utils import read_json
from basepair.plot.vdom import vdom_modisco
from kipoi.readers import HDF5Reader
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
from plotnine import *
mr = ModiscoResult(f"{modisco_dir}/modisco.h5")
mr.open()
# load the data
modisco_kwargs = read_json(os.path.join(modisco_dir, "kwargs.json"))
d = HDF5Reader(modisco_kwargs['imp_scores'])
d.open()
strand_dist_file = f"{modisco_dir}/strand_distances.h5"
if modisco_kwargs.get("ignore_strand_dist", False) and os.path.exists(strand_dist_file):
included_samples = HDF5Reader.load(strand_dist_file)['included_samples']
else:
included_samples = np.ones(d.f['inputs'].shape[:1], dtype=bool)
if modisco_kwargs.get("filter_npy", None) is not None:
included_samples = np.load(modisco_kwargs['filter_npy']) * included_samples
id_hash = pd.DataFrame({"peak_id": d.f['/metadata/interval_from_task'][:][included_samples],
"example_idx": np.arange(d.f['/metadata/interval_from_task'][included_samples].shape[0])})
tasks = list(d.f["targets"]["profile"].keys())
# get all seqlet instances
dfp = mr.seqlet_df_instances().rename(columns=dict(seqname="example_idx"))
dfp = pd.merge(dfp,id_hash, on="example_idx")
# row = example_idx
total_counts = pd.DataFrame({task: d.f[f"/targets/profile/{task}"][:][included_samples].sum(axis=-1).sum(axis=-1)
for task in tasks
})
len(mr.patterns())
# Number of metaclusters
len(mr.metaclusters())
Number of seqlets per pattern¶
mc_stat = mr.metacluster_stats()
ggplot(aes(x="pattern", y='n'), mc_stat) + geom_bar(stat='identity') + \
facet_wrap("~metacluster", ncol=4, labeller='label_both') + \
ylab("Number of seqlets") + theme_classic()

Zoom-into the 500 seqlet range¶
ggplot(aes(x="pattern", y='n'), mc_stat) + geom_bar(stat='identity') + \
facet_wrap("~metacluster", ncol=4, labeller='label_both') + \
ylab("Number of seqlets") + theme_classic() + coord_cartesian(ylim=[0, 500])

Important tasks per metacluster¶
mcs_grouped = mc_stat.groupby("metacluster").n.agg(["count", "sum"]).reset_index()
fig, ax = plt.subplots(2, 1, sharex=False, figsize=(18,6),
gridspec_kw={'height_ratios': [2,1]})
mcs_grouped.plot("metacluster", "count",
label="# patterns per metacluster", style="o--",
ax=ax[0],
yticks=range(mcs_grouped['count'].max()+1),
xticks=range(38),
fontsize='large',
xlim=(-.5, len(mr.metaclusters()) - .5 ))
mcs_grouped.plot("metacluster", "sum",
label="# seqlets per metacluster",
style="o--", ax=ax[0], secondary_y=True)
ax[0].grid(linewidth=0.2)
mr.plot_metacluster_activity(ax[1], cbar=False)
ax[1].set_title("Importance score activity: Red = positive, Blue = negative");

vdom_modisco(mr, url_dir, total_counts, dfp, is_open=True, trim_frac=0.08, letter_width=0.15, height=0.5)
metacluster_0, # patterns: 1, # seqlets: 1191, important for: Klf4
pattern_0: # seqlets: 1191

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 1127 / 98428 regions (1.1%)

metacluster_1, # patterns: 2, # seqlets: 687, important for: Nanog,Sox2
pattern_0: # seqlets: 330

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 323 / 98428 regions (0.3%)

pattern_1: # seqlets: 357

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 341 / 98428 regions (0.3%)

metacluster_2, # patterns: 1, # seqlets: 364, important for: Klf4,-Sox2
pattern_0: # seqlets: 364

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence

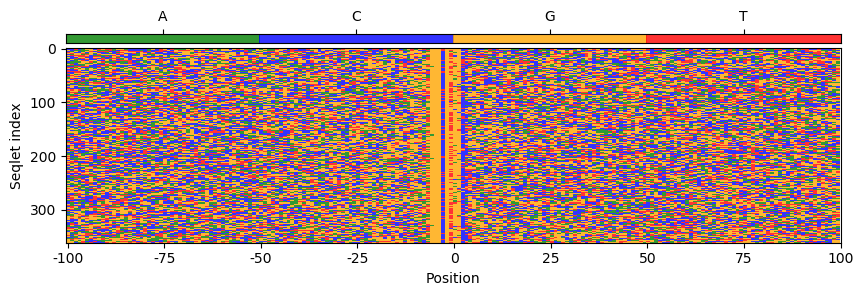
ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 358 / 98428 regions (0.4%)

metacluster_3, # patterns: 1, # seqlets: 218, important for: Nanog
pattern_0: # seqlets: 218

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 217 / 98428 regions (0.2%)

metacluster_4, # patterns: 2, # seqlets: 500, important for: Nanog,Oct4,Sox2
pattern_0: # seqlets: 386

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 373 / 98428 regions (0.4%)

pattern_1: # seqlets: 114

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 112 / 98428 regions (0.1%)

metacluster_5, # patterns: 5, # seqlets: 706, important for: Klf4,Nanog,Oct4,Sox2
pattern_0: # seqlets: 225

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 220 / 98428 regions (0.2%)

pattern_1: # seqlets: 176

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 172 / 98428 regions (0.2%)

pattern_2: # seqlets: 131

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 128 / 98428 regions (0.1%)

pattern_3: # seqlets: 90

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 90 / 98428 regions (0.1%)

pattern_4: # seqlets: 84

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 84 / 98428 regions (0.1%)

metacluster_7, # patterns: 2, # seqlets: 352, important for: Oct4,Sox2
pattern_0: # seqlets: 230

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence

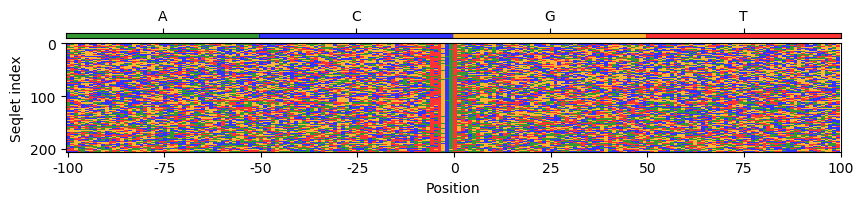
ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 224 / 98428 regions (0.2%)

pattern_1: # seqlets: 122

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 121 / 98428 regions (0.1%)

metacluster_8, # patterns: 2, # seqlets: 313, important for: Klf4,Nanog,Sox2
pattern_0: # seqlets: 241

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 237 / 98428 regions (0.2%)

pattern_1: # seqlets: 72

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 72 / 98428 regions (0.1%)

metacluster_10, # patterns: 1, # seqlets: 188, important for: Klf4,Oct4,Sox2
pattern_0: # seqlets: 188

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 183 / 98428 regions (0.2%)

metacluster_12, # patterns: 1, # seqlets: 198, important for: Sox2
pattern_0: # seqlets: 198

Aggregated profiles and contribution scores)

Aggregated hypothetical contribution scores)

Sequence


ChIP-nexus counts


Importance scores (profile)

Importance scores (counts)

Positional distribution


Total count distribution
Pattern occurs in 193 / 98428 regions (0.2%)

print("Metaclusters heatmap")
import seaborn as sns
activity_patterns = np.array(mr.f.f['metaclustering_results']['attribute_vectors'])[
np.array(
[x[0] for x in sorted(
enumerate(mr.f.f['metaclustering_results']['metacluster_indices']),
key=lambda x: x[1])])]
sns.heatmap(activity_patterns, center=0);
