BPNet tf-Modisco report¶
In [1]:
url_dir = "http://mitra.stanford.edu/kundaje/avsec/chipnexus/oct-sox-nanog-klf/models/n_dil_layers=9/modisco/valid/plots/"
modisco_dir = "/users/avsec/workspace/basepair/data/processed/chipnexus/exp/models/oct-sox-nanog-klf/models/n_dil_layers=9/modisco/valid"
In [2]:
# Parameters
url_dir = "http://mitra.stanford.edu/kundaje/avsec/chipnexus/oct-sox-nanog-klf-dnase/models/n_dil_layers=9/modisco/valid/plots/"
modisco_dir = "."
In [3]:
from basepair.modisco import ModiscoResult
from basepair.config import get_data_dir
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from plotnine import *
In [4]:
mr = ModiscoResult(f"{modisco_dir}/modisco.h5")
mr.open()
In [5]:
# Number of patterns
len(mr.patterns())
Out[5]:
In [6]:
# Number of metaclusters
len(mr.metaclusters())
Out[6]:
Number of seqlets per pattern¶
In [7]:
mc_stat = mr.metacluster_stats()
In [8]:
ggplot(aes(x="pattern", y='n'), mc_stat) + geom_bar(stat='identity') + \
facet_wrap("~metacluster", ncol=4, labeller='label_both') + \
ylab("Number of seqlets") + theme_classic()

Out[8]:
Zoom-into the 500 seqlet range¶
In [9]:
ggplot(aes(x="pattern", y='n'), mc_stat) + geom_bar(stat='identity') + \
facet_wrap("~metacluster", ncol=4, labeller='label_both') + \
ylab("Number of seqlets") + theme_classic() + coord_cartesian(ylim=[0, 500])

Out[9]:
Important tasks per metacluster¶
In [10]:
mcs_grouped = mc_stat.groupby("metacluster").n.agg(["count", "sum"]).reset_index()
fig, ax = plt.subplots(2, 1, sharex=False, figsize=(18,6),
gridspec_kw={'height_ratios': [2,1]})
mcs_grouped.plot("metacluster", "count",
label="# patterns per metacluster", style="o--",
ax=ax[0],
yticks=range(mcs_grouped['count'].max()+1),
xticks=range(38),
fontsize='large',
xlim=(-.5, len(mr.metaclusters()) - .5 ))
mcs_grouped.plot("metacluster", "sum",
label="# seqlets per metacluster",
style="o--", ax=ax[0], secondary_y=True)
ax[0].grid(linewidth=0.2)
mr.plot_metacluster_activity(ax[1], cbar=False)
ax[1].set_title("Importance score activity: Red = positive, Blue = negative");

In [11]:
mr.vdom(url_dir, is_open=True, trim_frac=0.08, letter_width=0.15, height=0.5)
Out[11]:
metacluster_0, # patterns: 15, # seqlets: 8594, important for: DNase,Klf4,Nanog,Oct4,Sox2
pattern_0: # seqlets: 2697

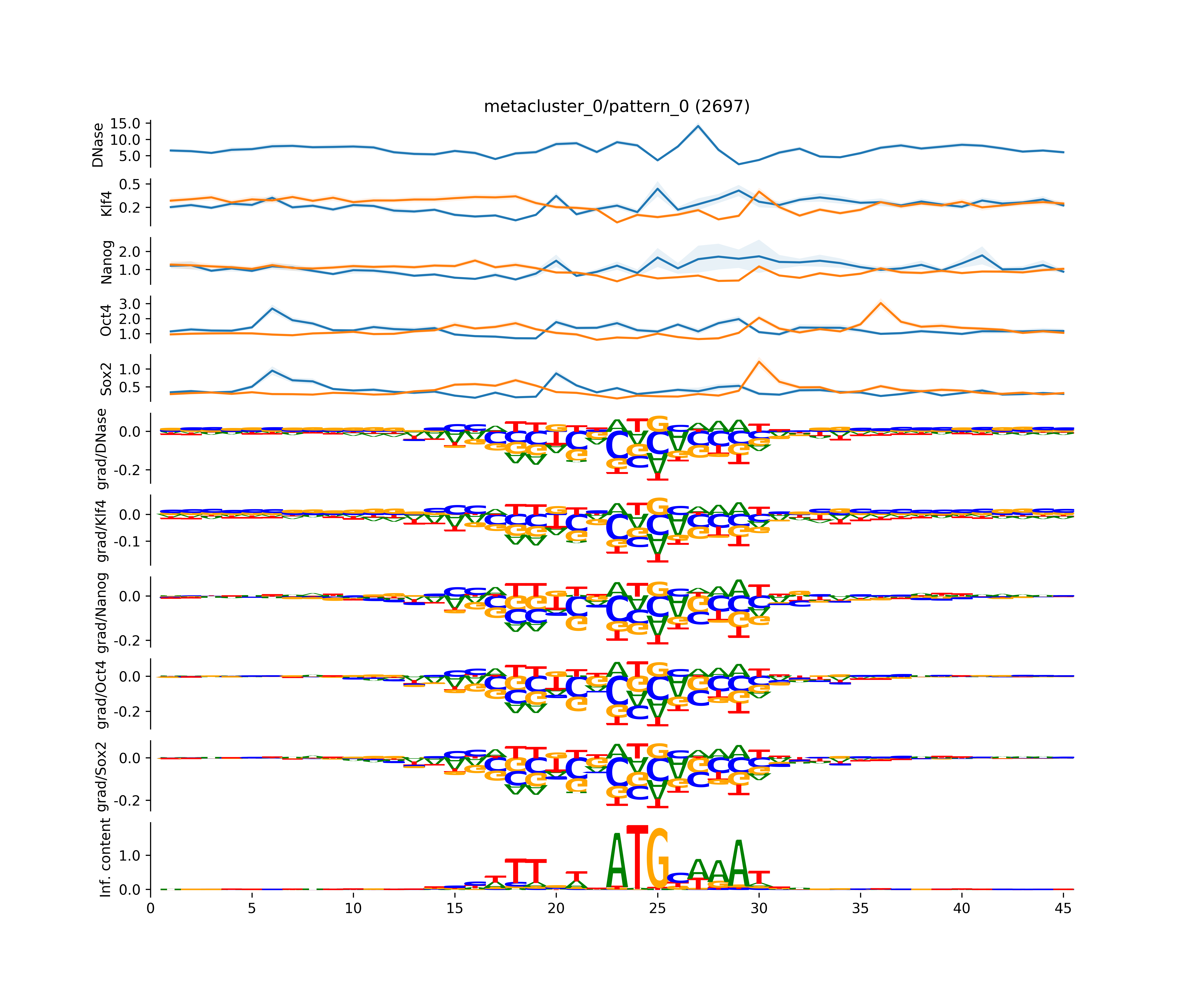
pattern_1: # seqlets: 1764

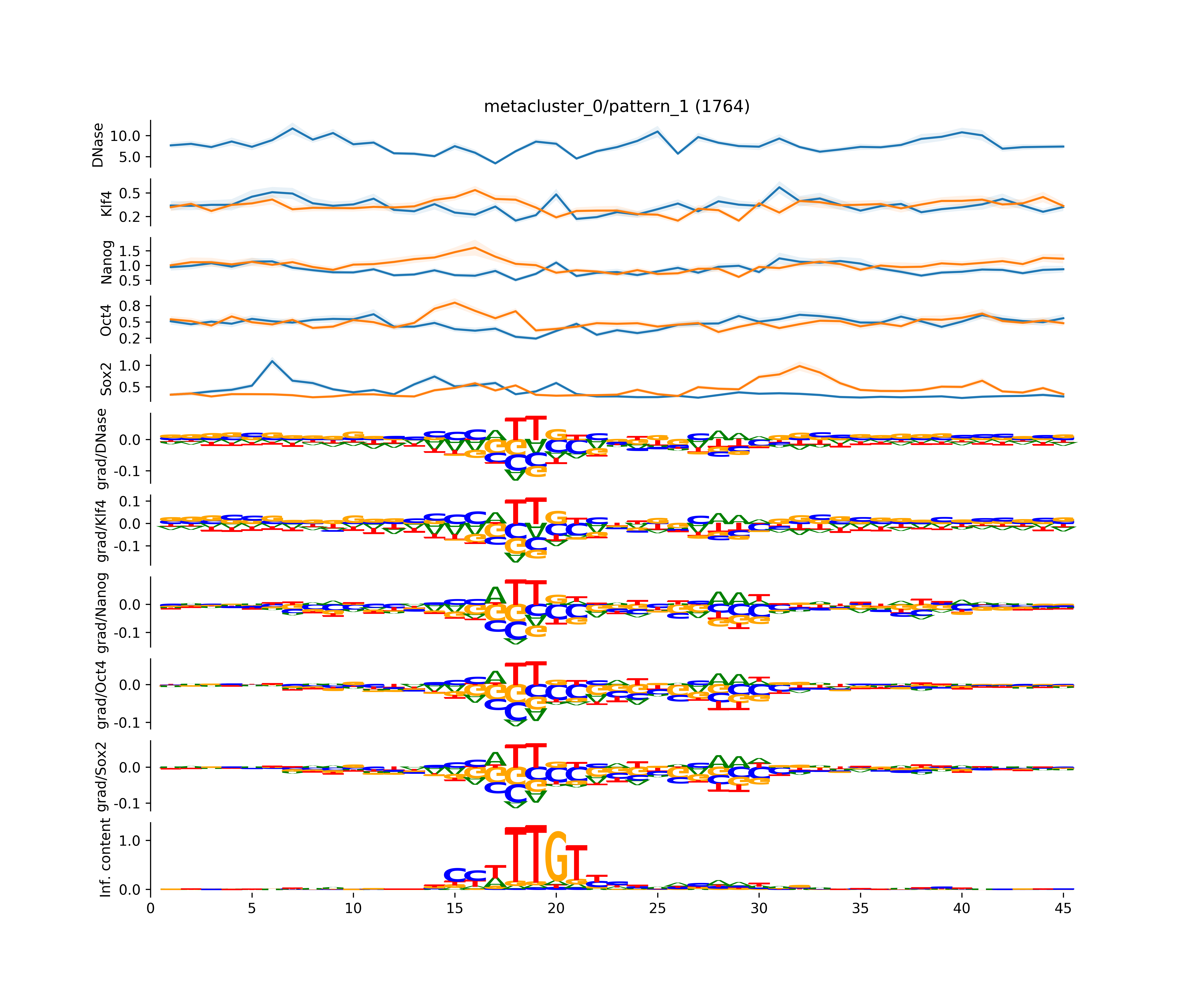
pattern_2: # seqlets: 1417

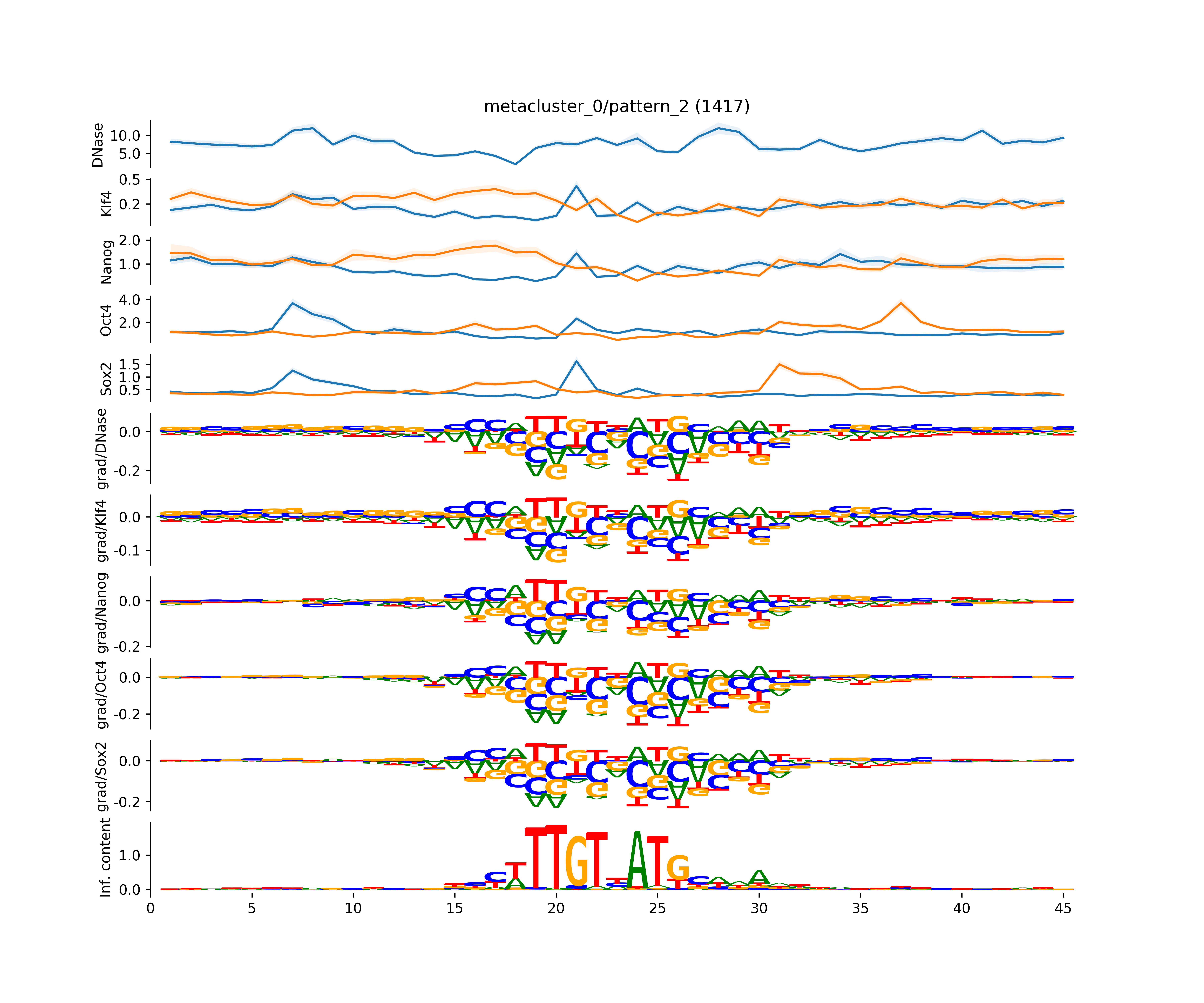
pattern_3: # seqlets: 546

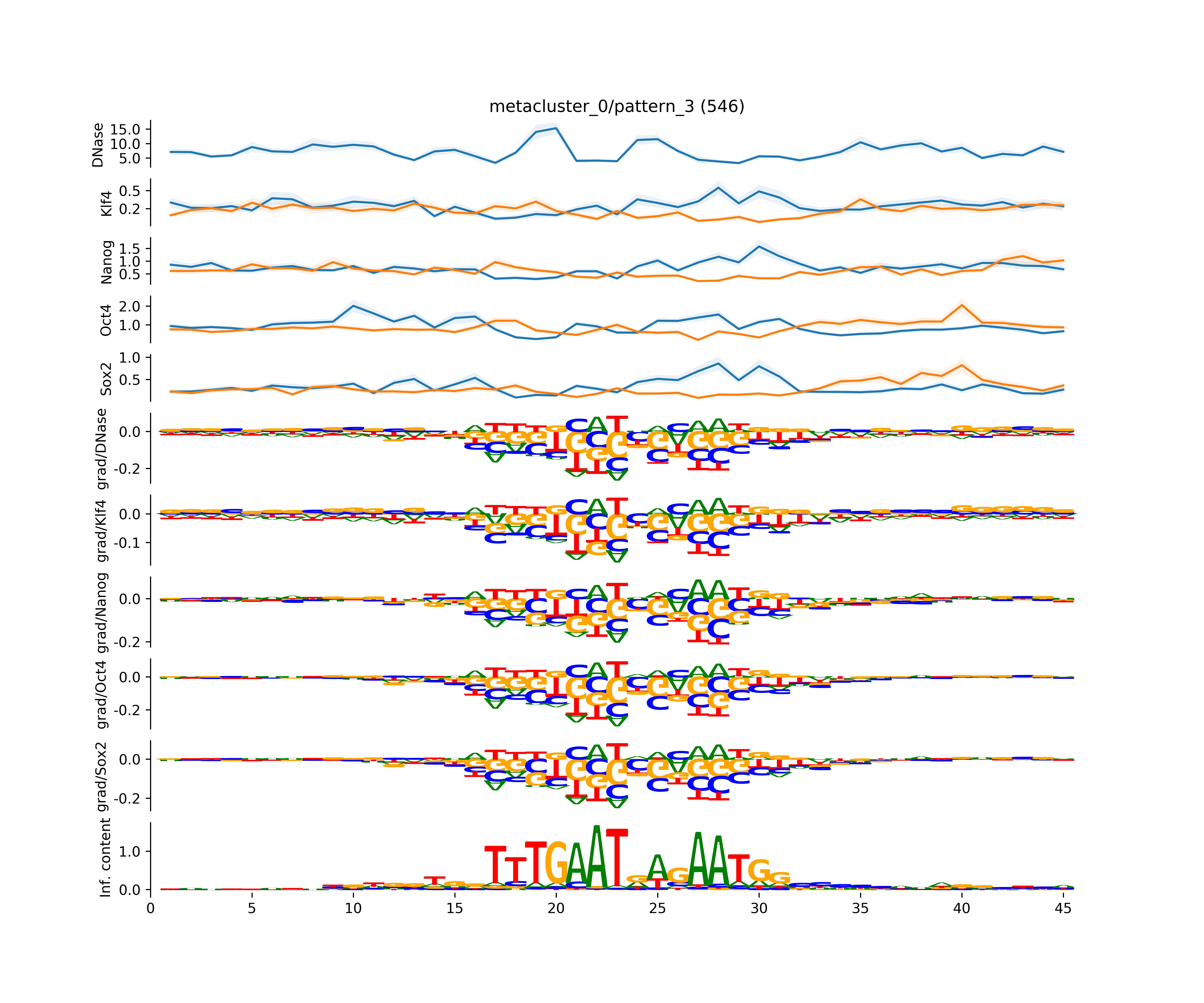
pattern_4: # seqlets: 314

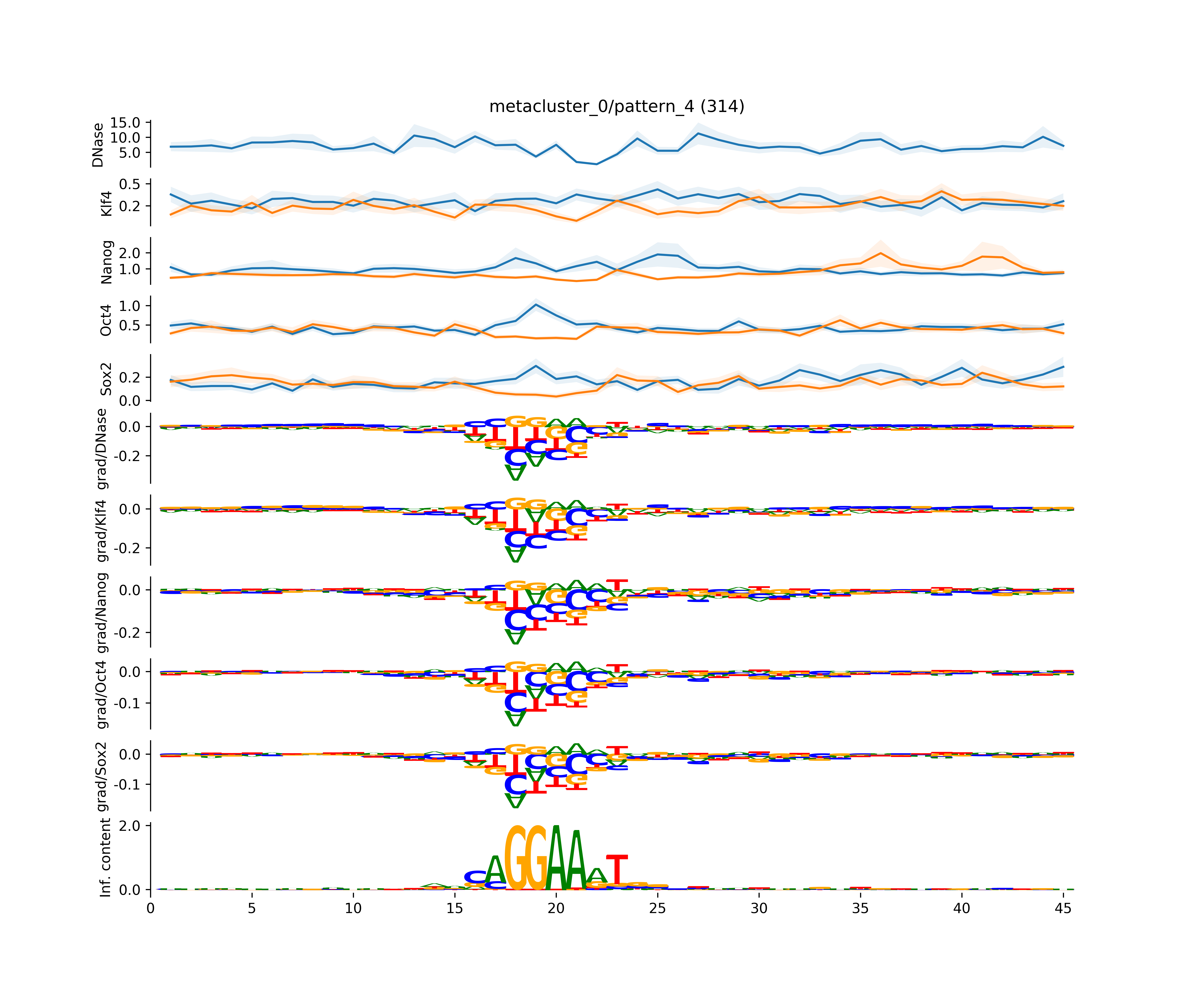
pattern_5: # seqlets: 295

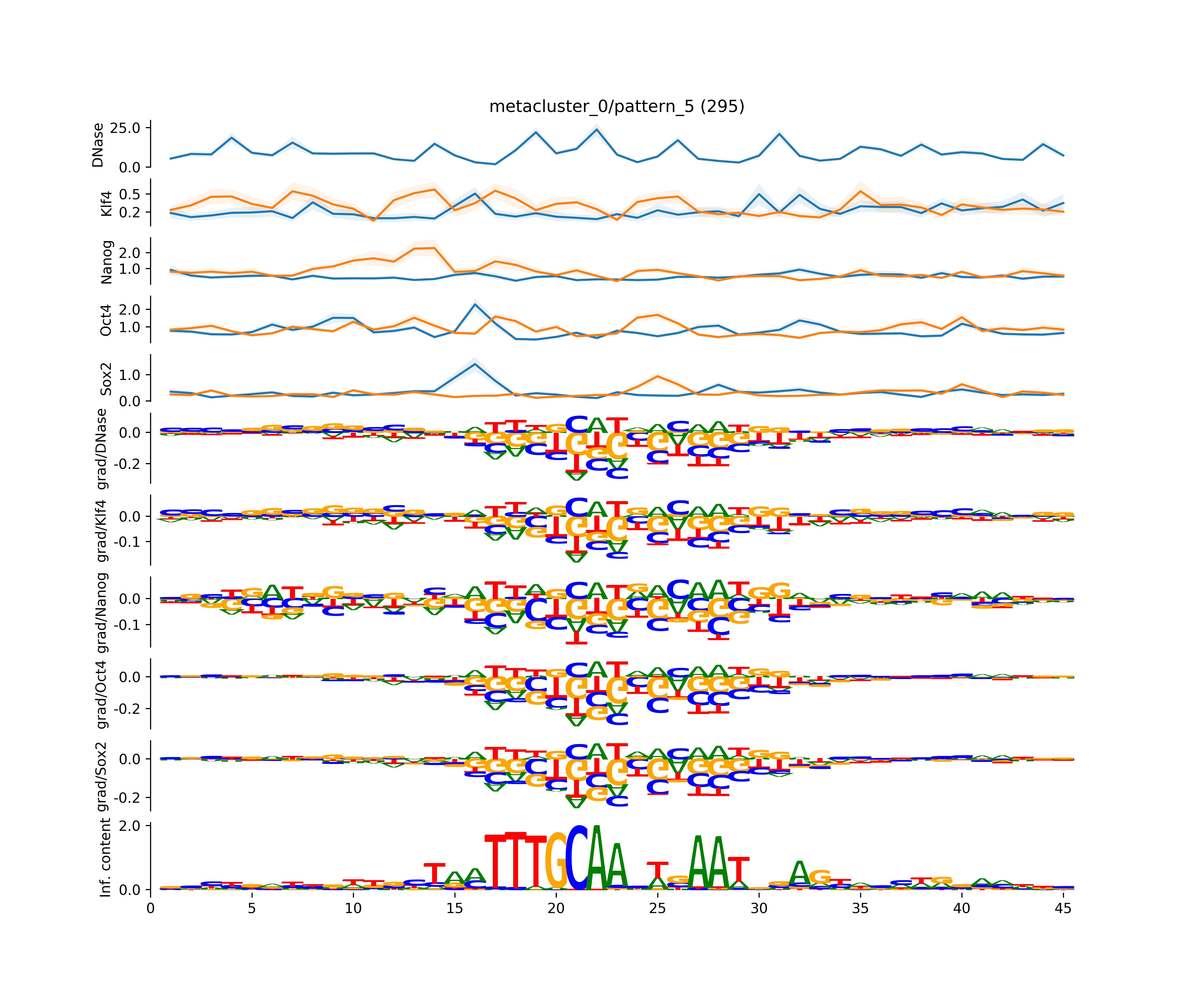
pattern_6: # seqlets: 244

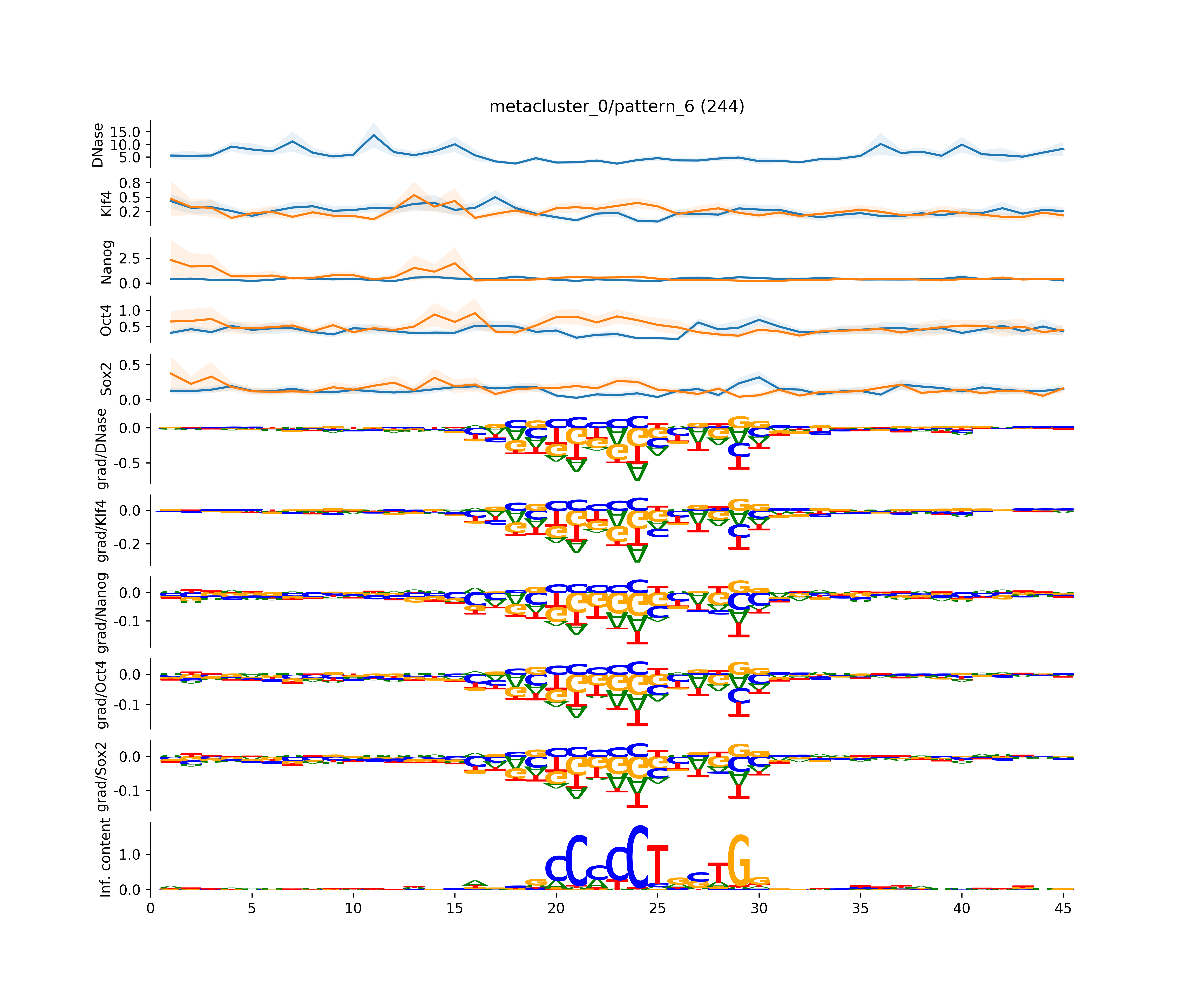
pattern_7: # seqlets: 229

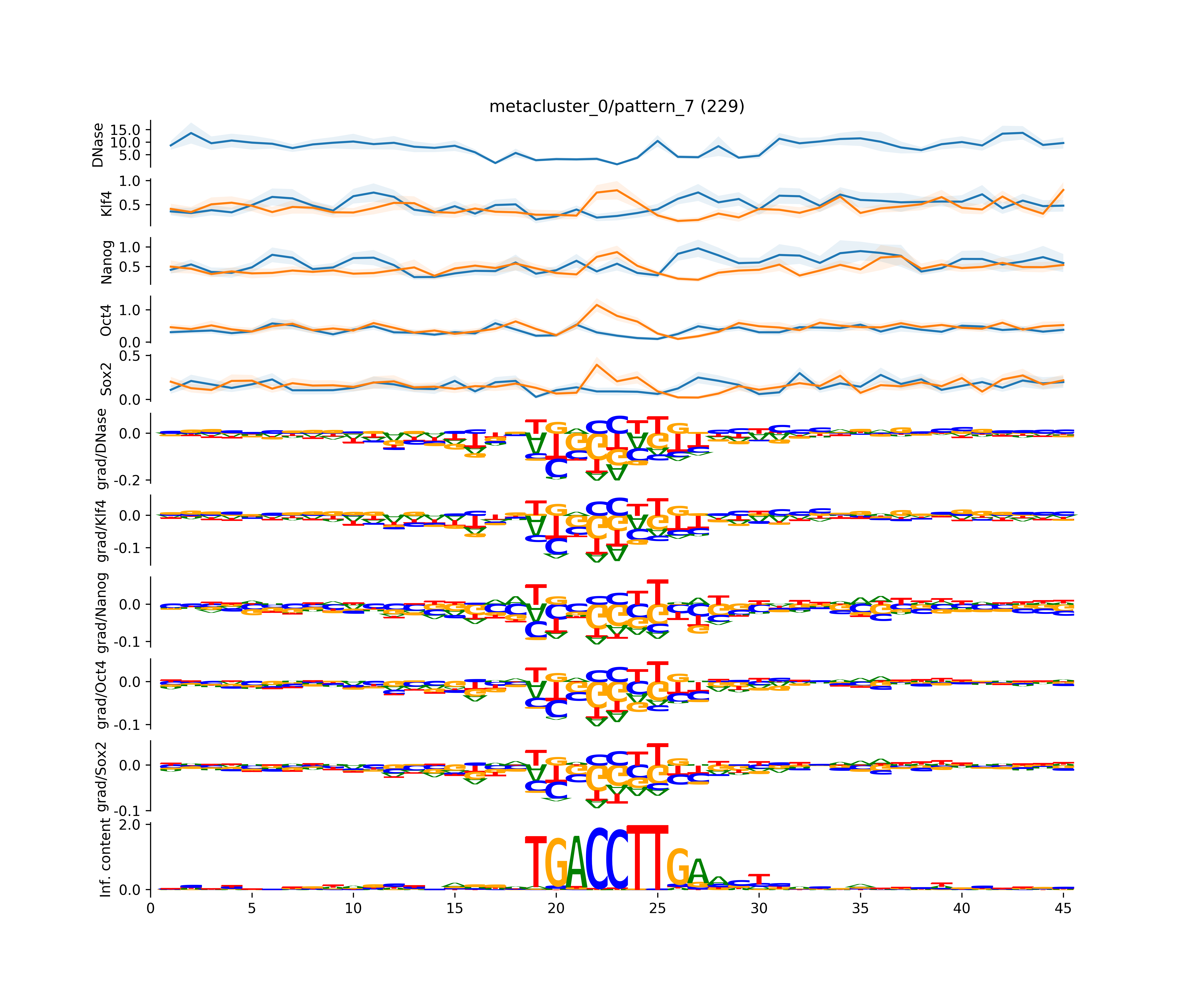
pattern_8: # seqlets: 225

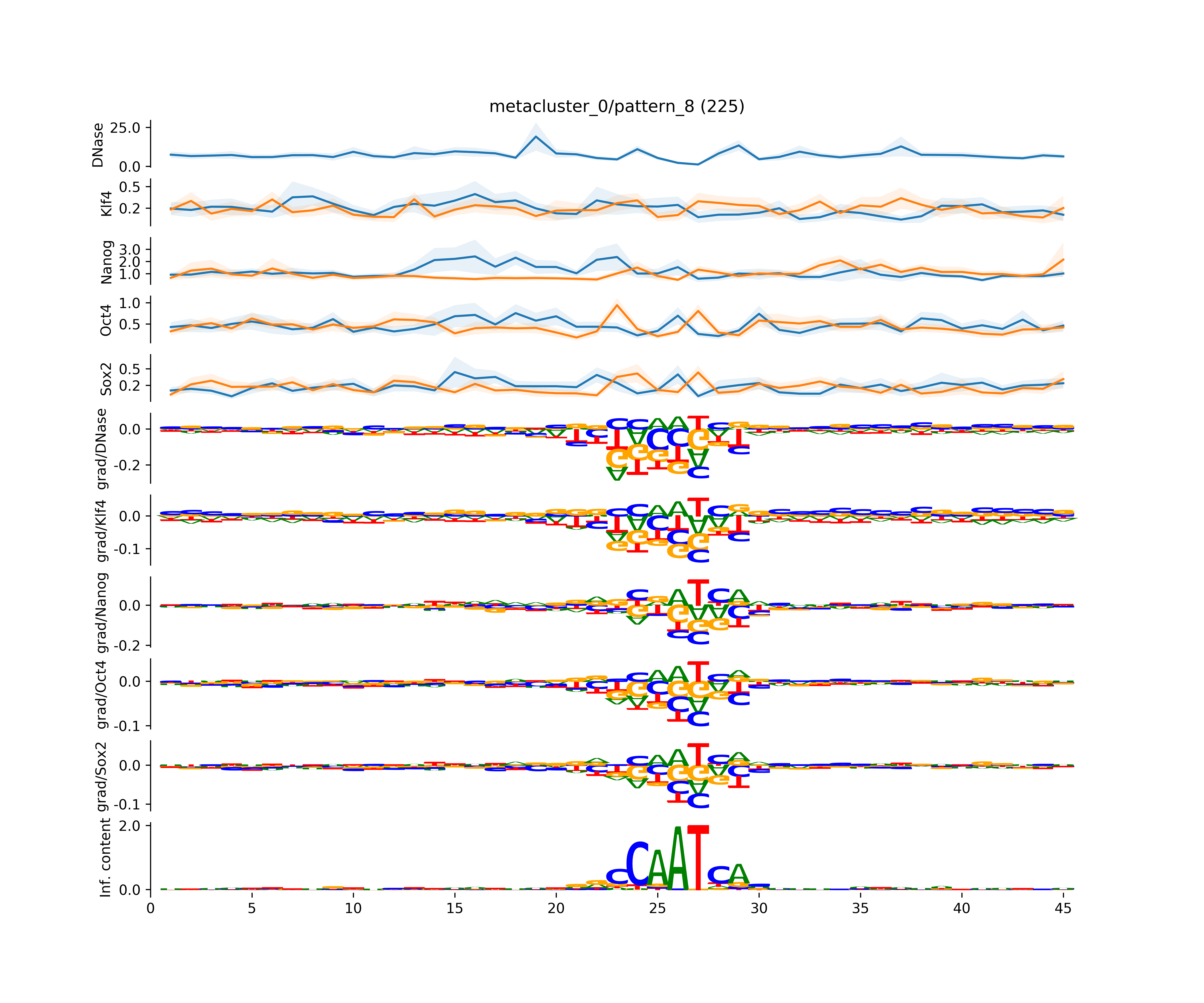
pattern_9: # seqlets: 165

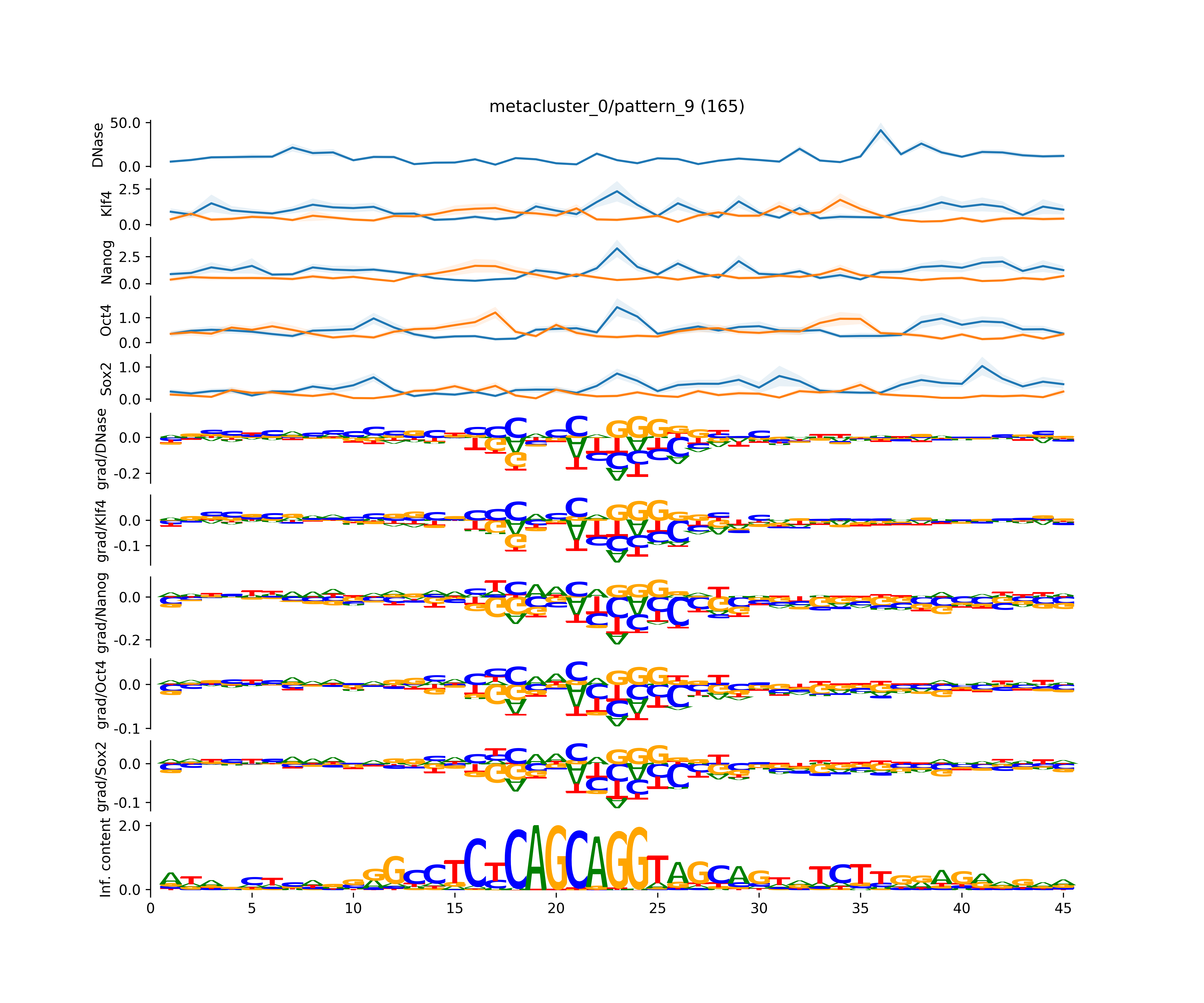
pattern_10: # seqlets: 162

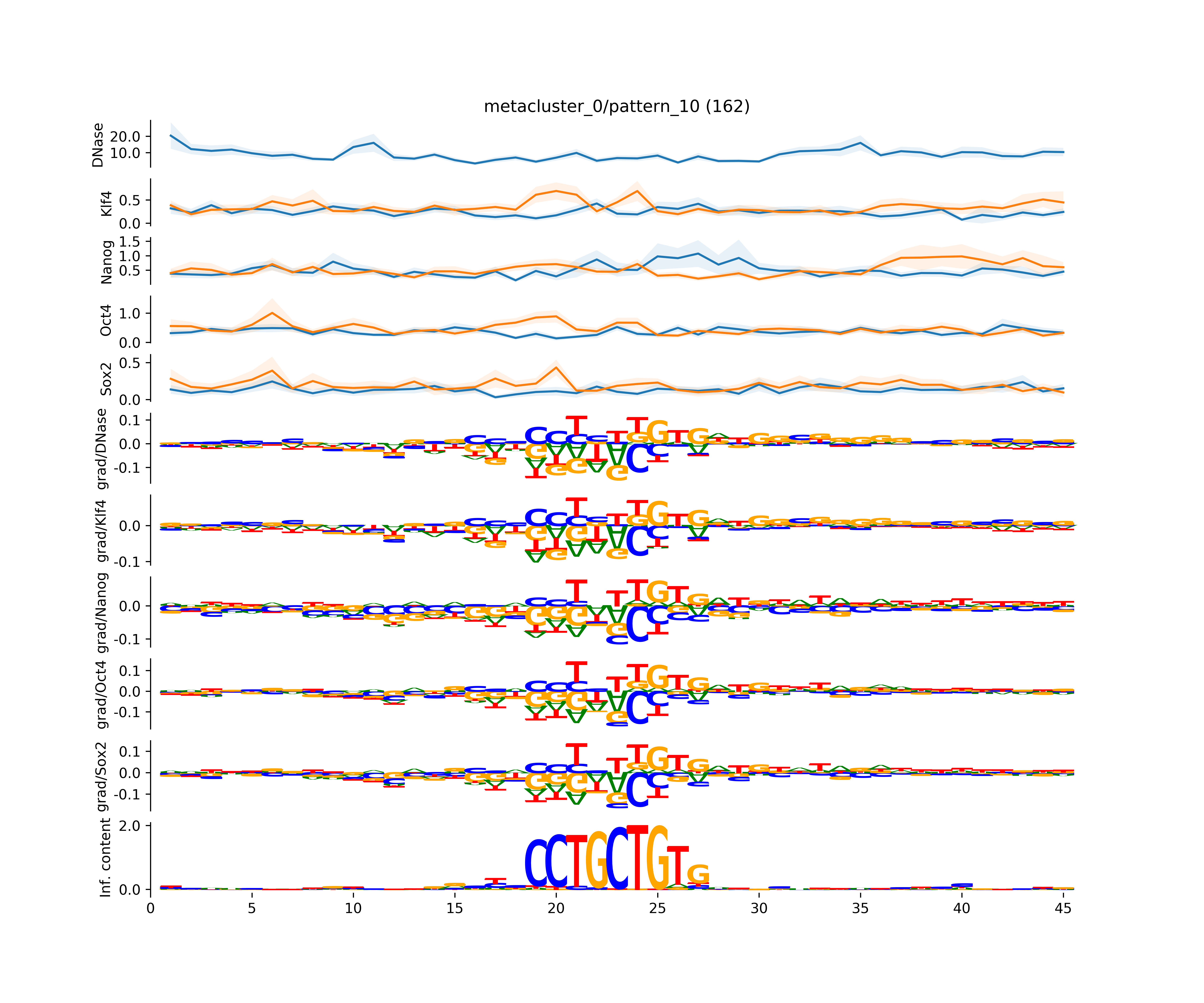
pattern_11: # seqlets: 159

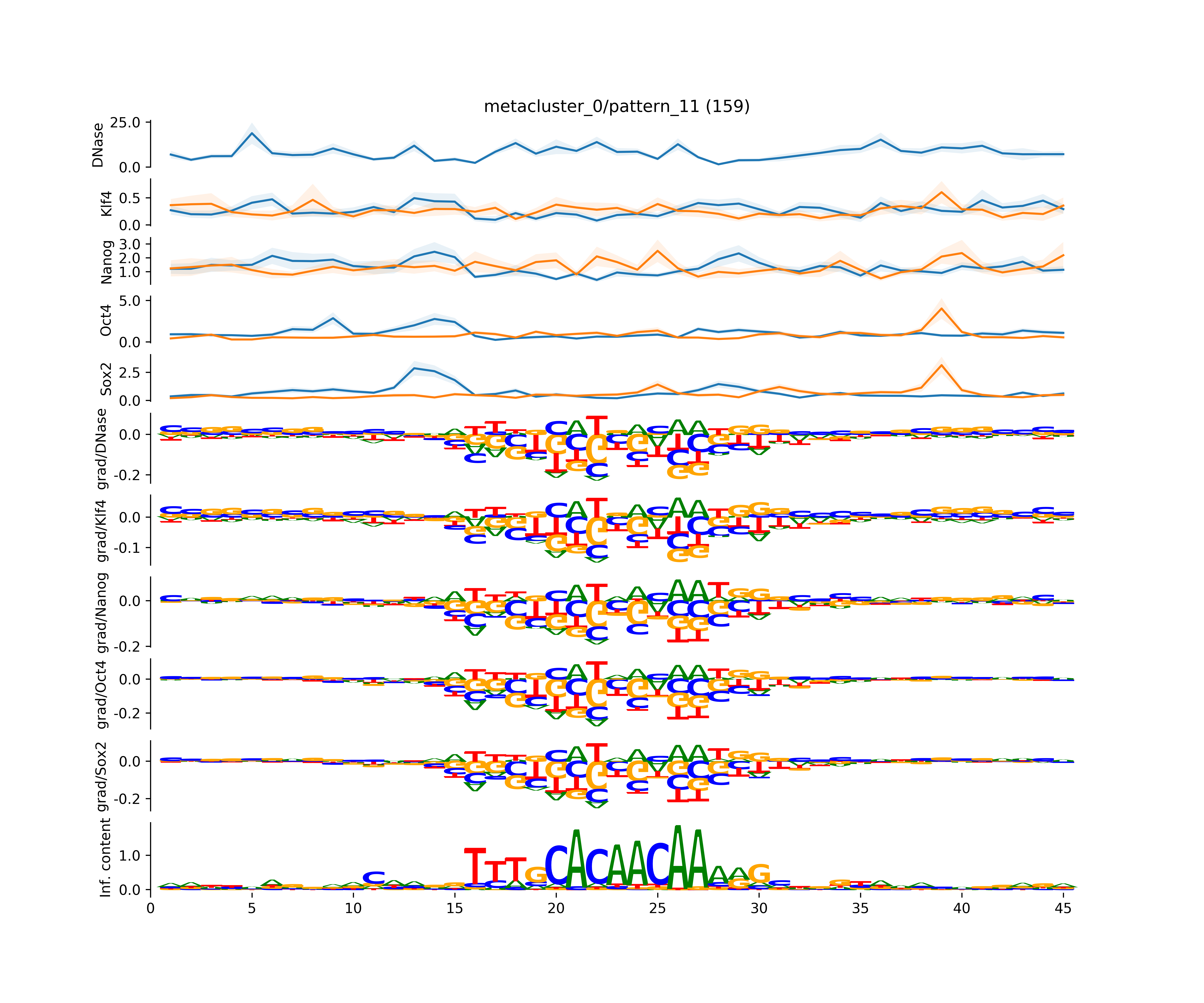
pattern_12: # seqlets: 148

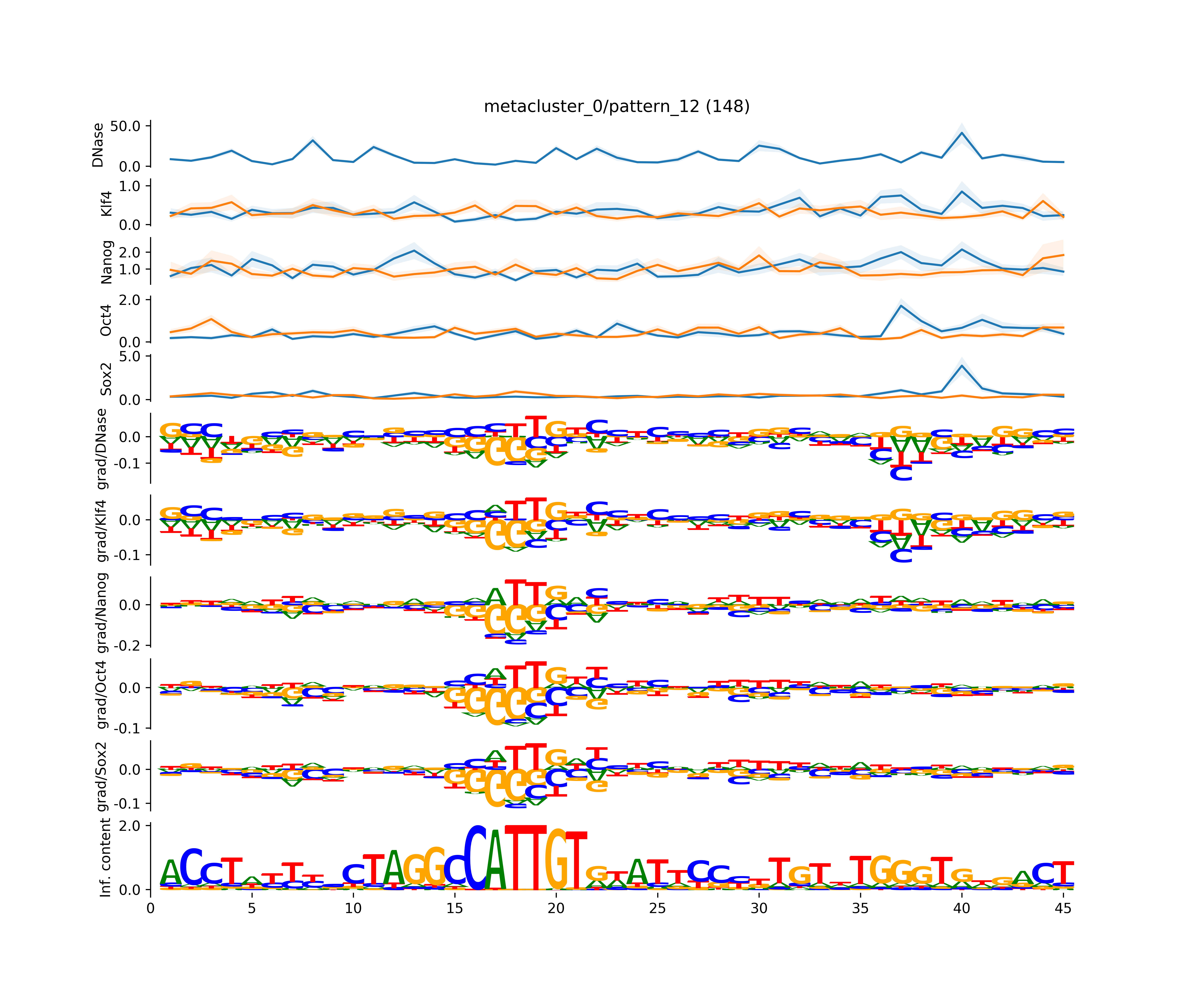
pattern_13: # seqlets: 127

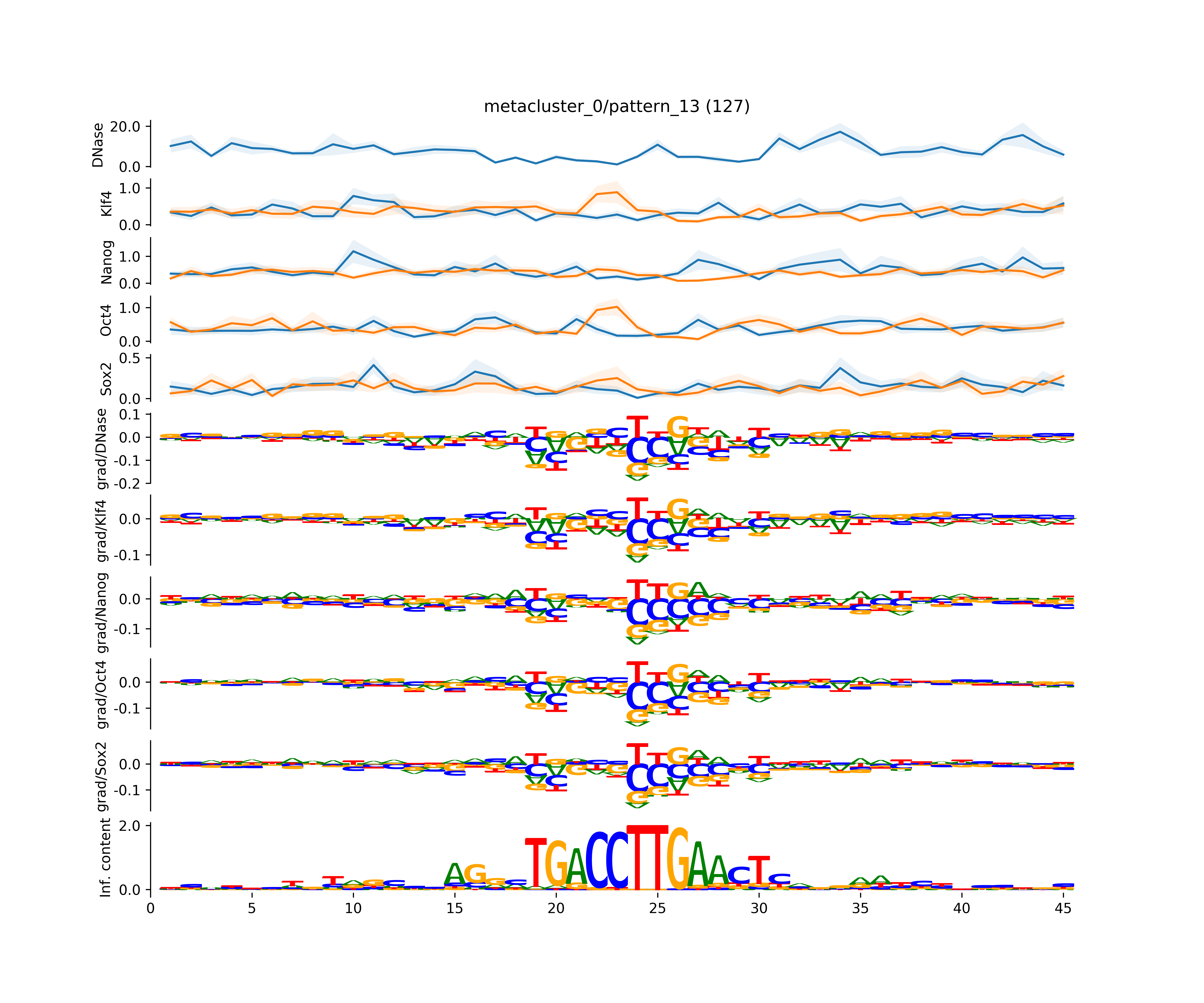
pattern_14: # seqlets: 102

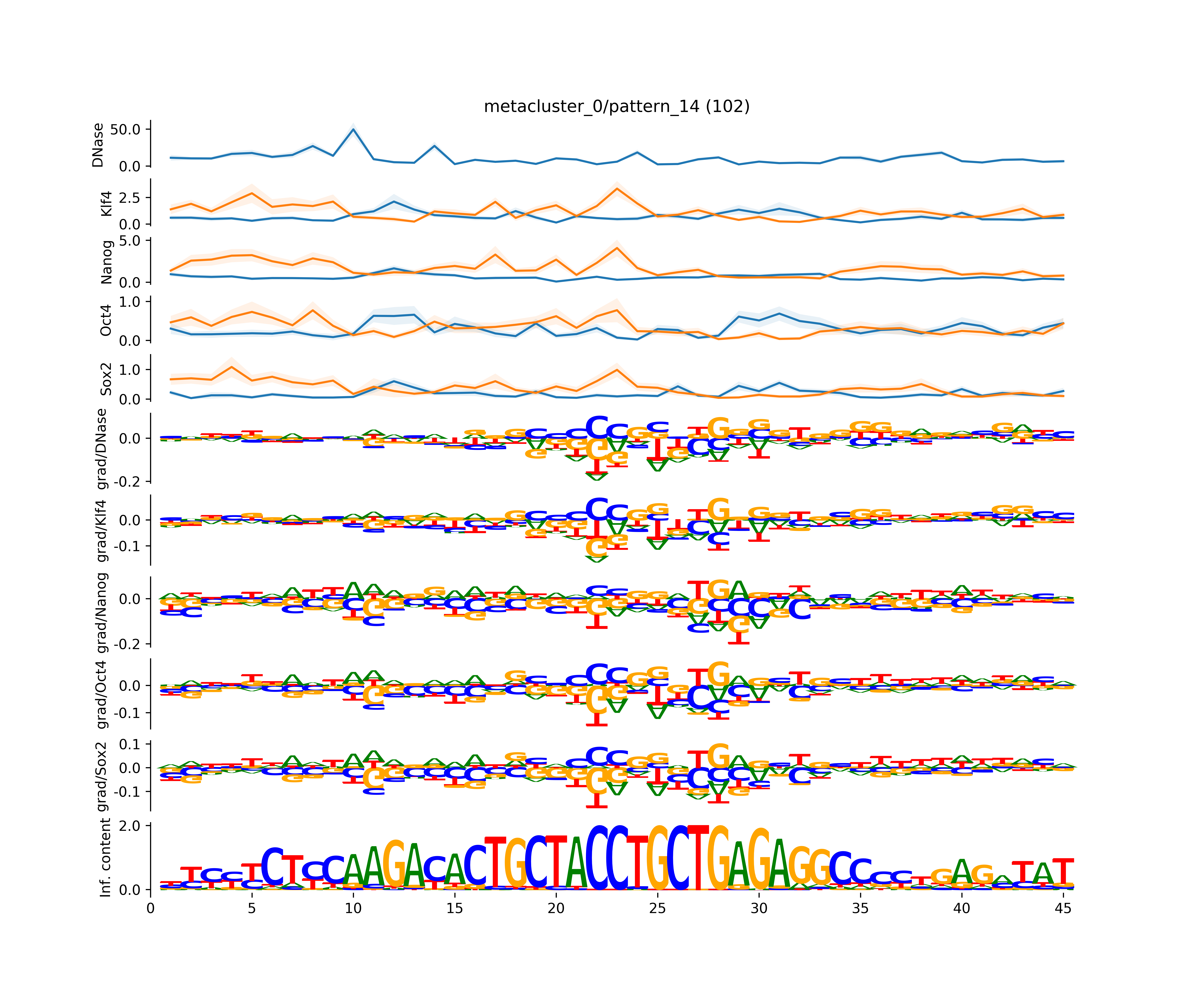
metacluster_1, # patterns: 4, # seqlets: 1842, important for: Nanog
pattern_0: # seqlets: 1409

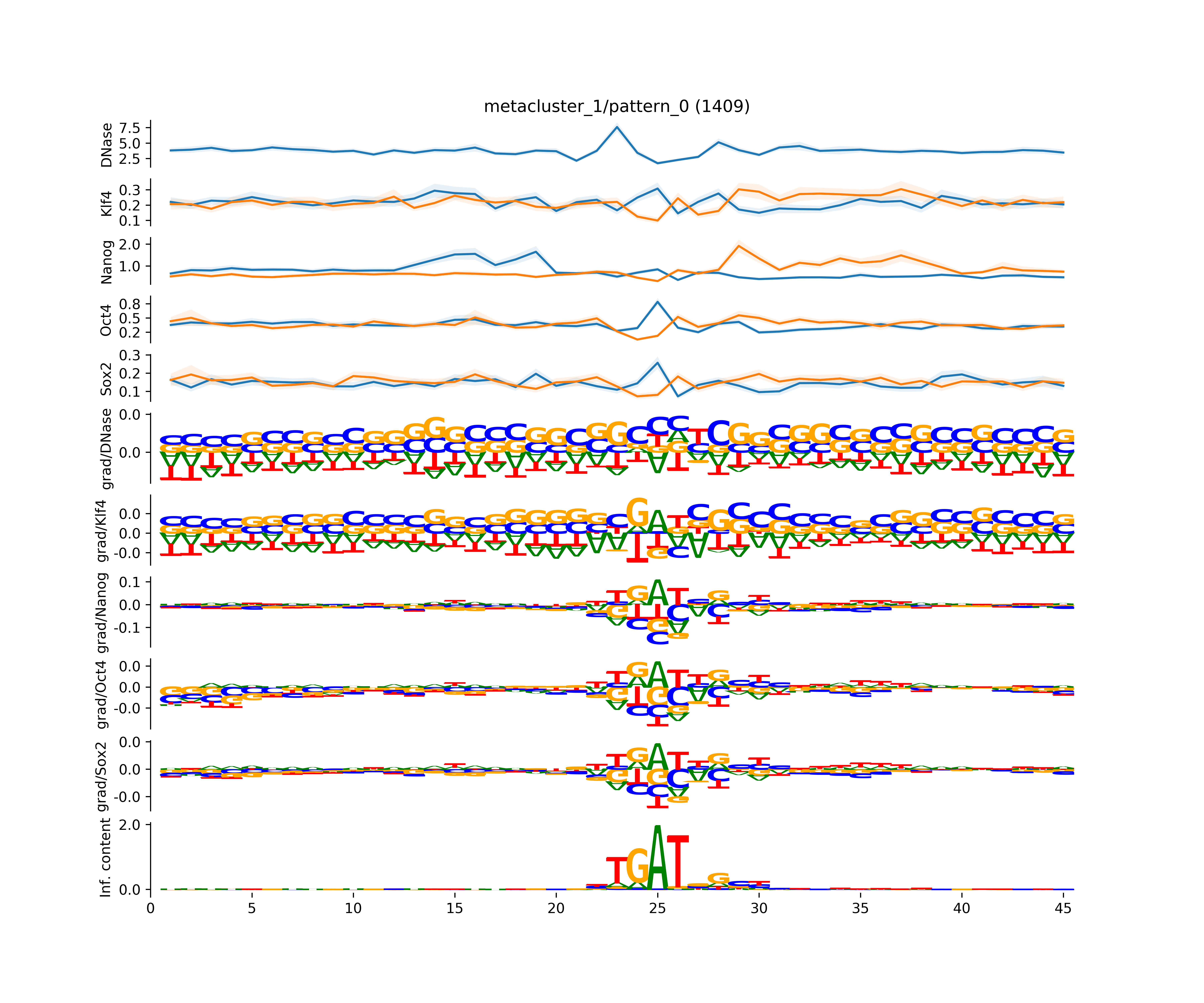
pattern_1: # seqlets: 232

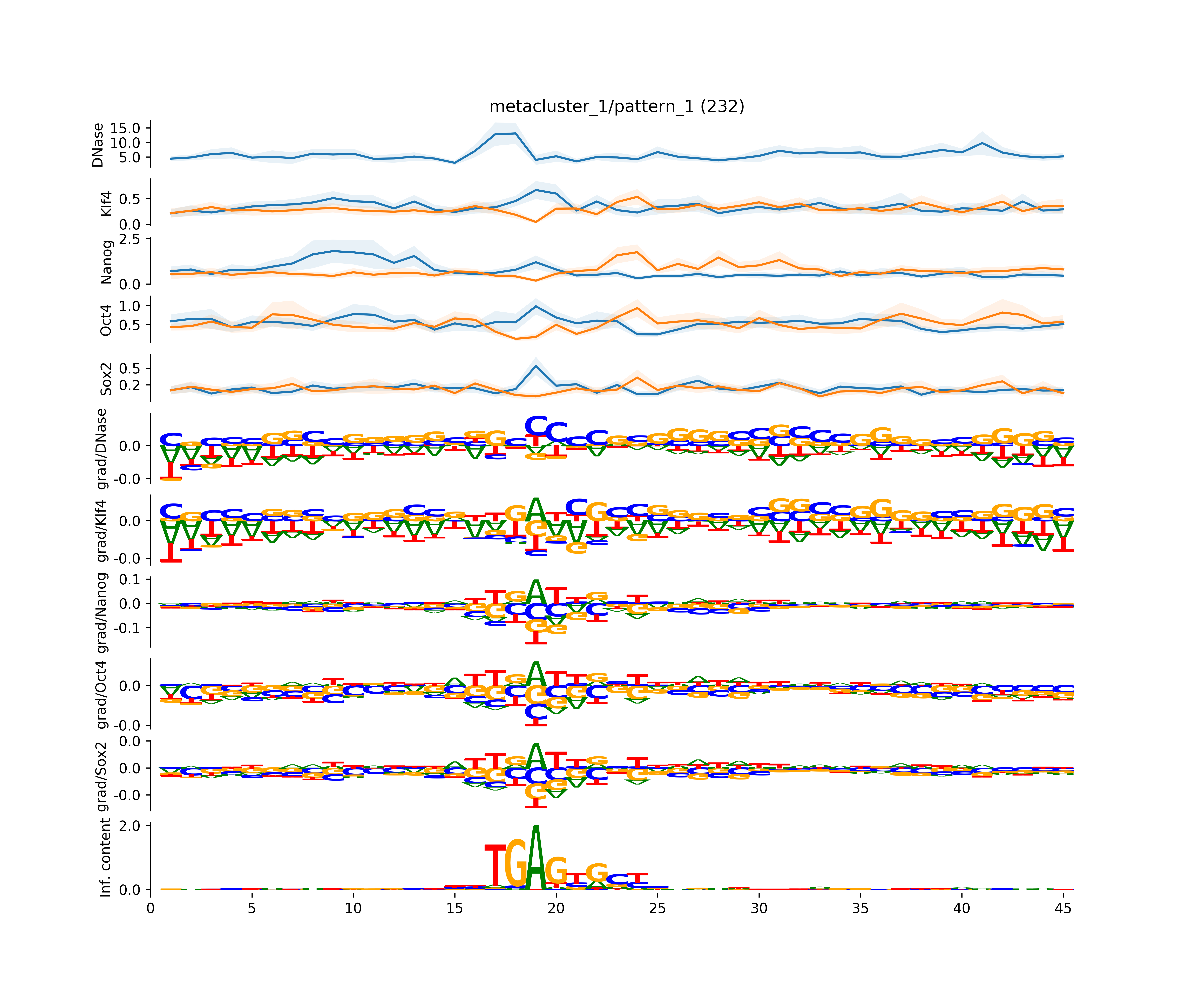
pattern_2: # seqlets: 133

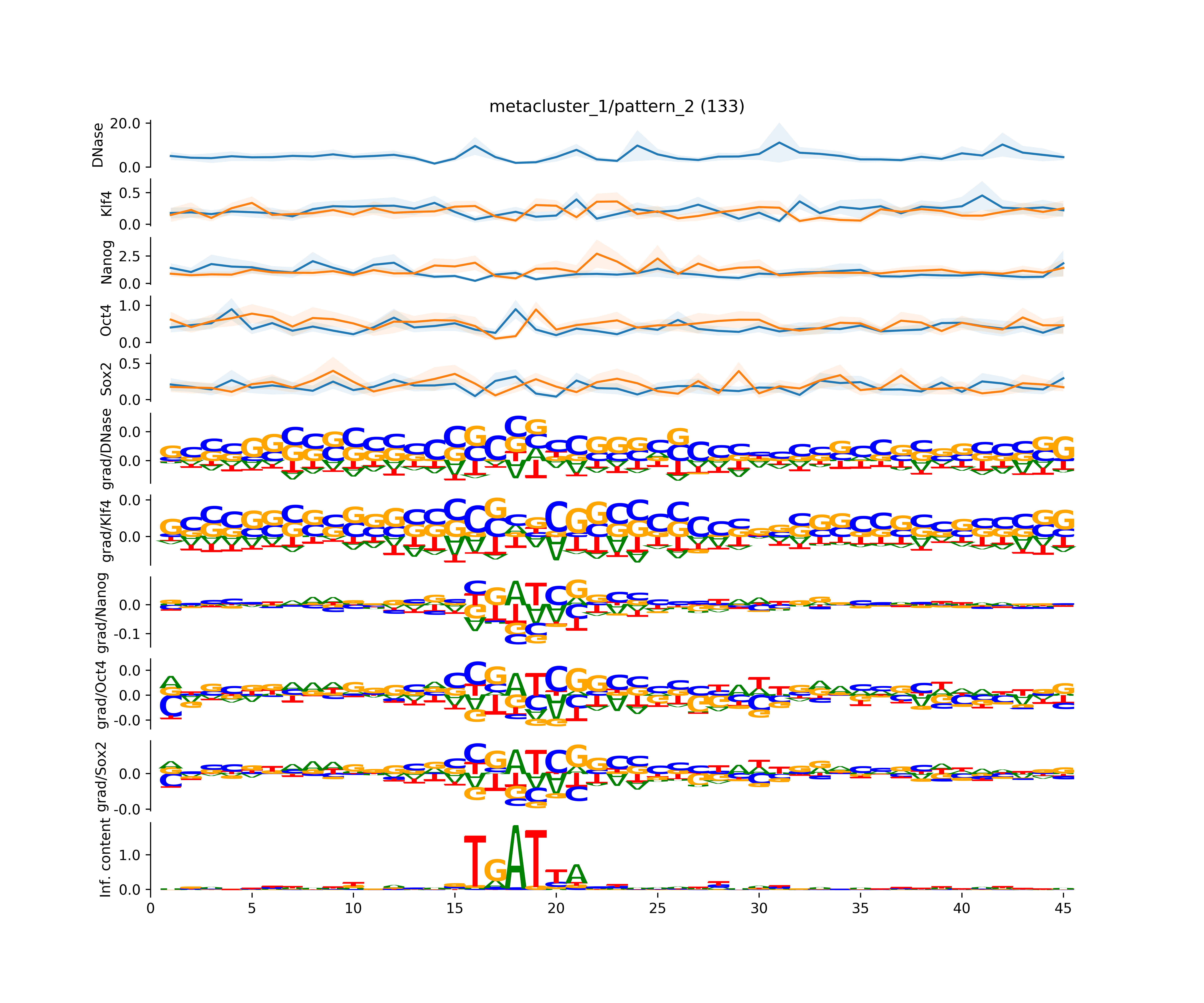
pattern_3: # seqlets: 68

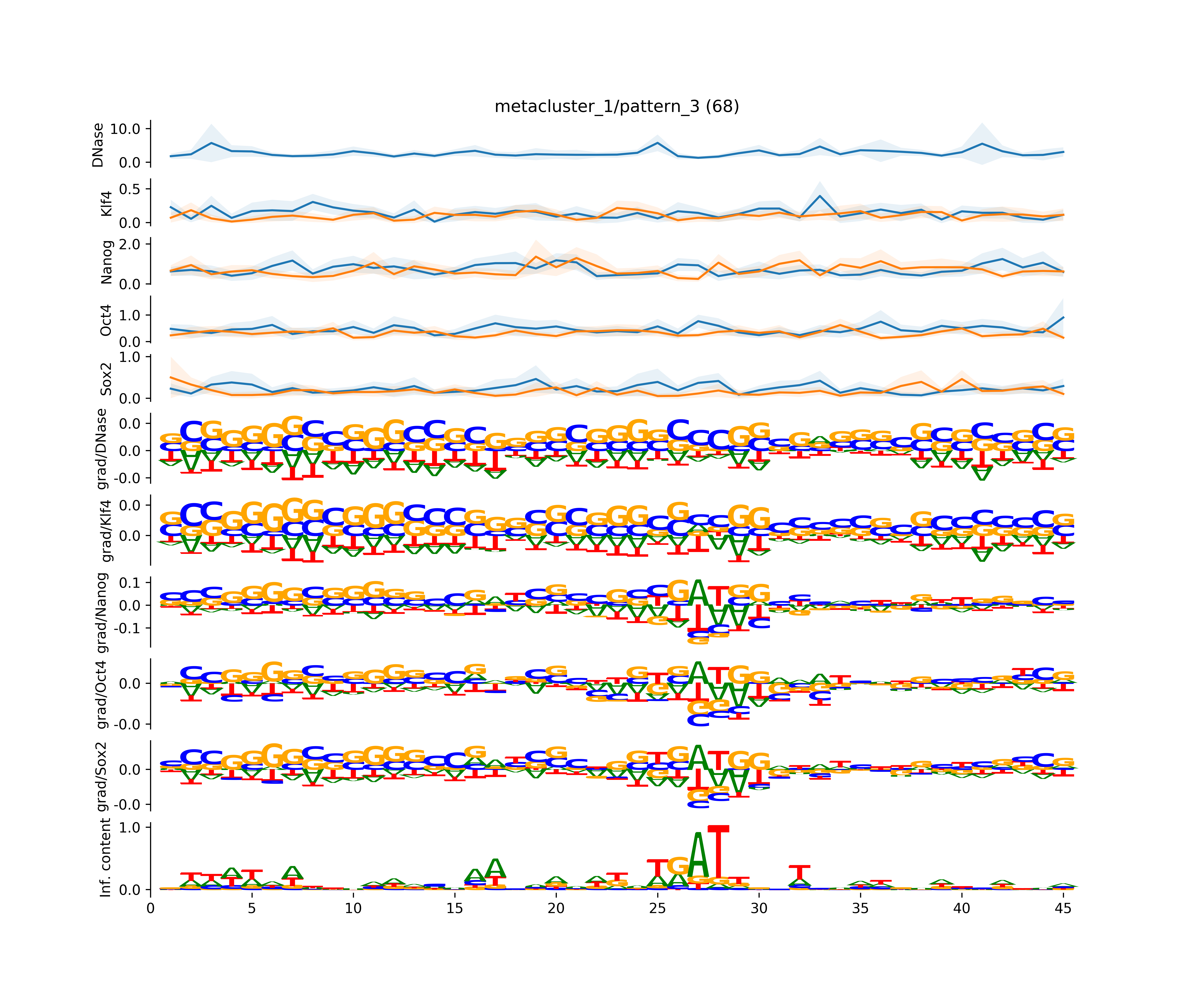
metacluster_2, # patterns: 6, # seqlets: 3063, important for: DNase,Klf4
pattern_0: # seqlets: 1761

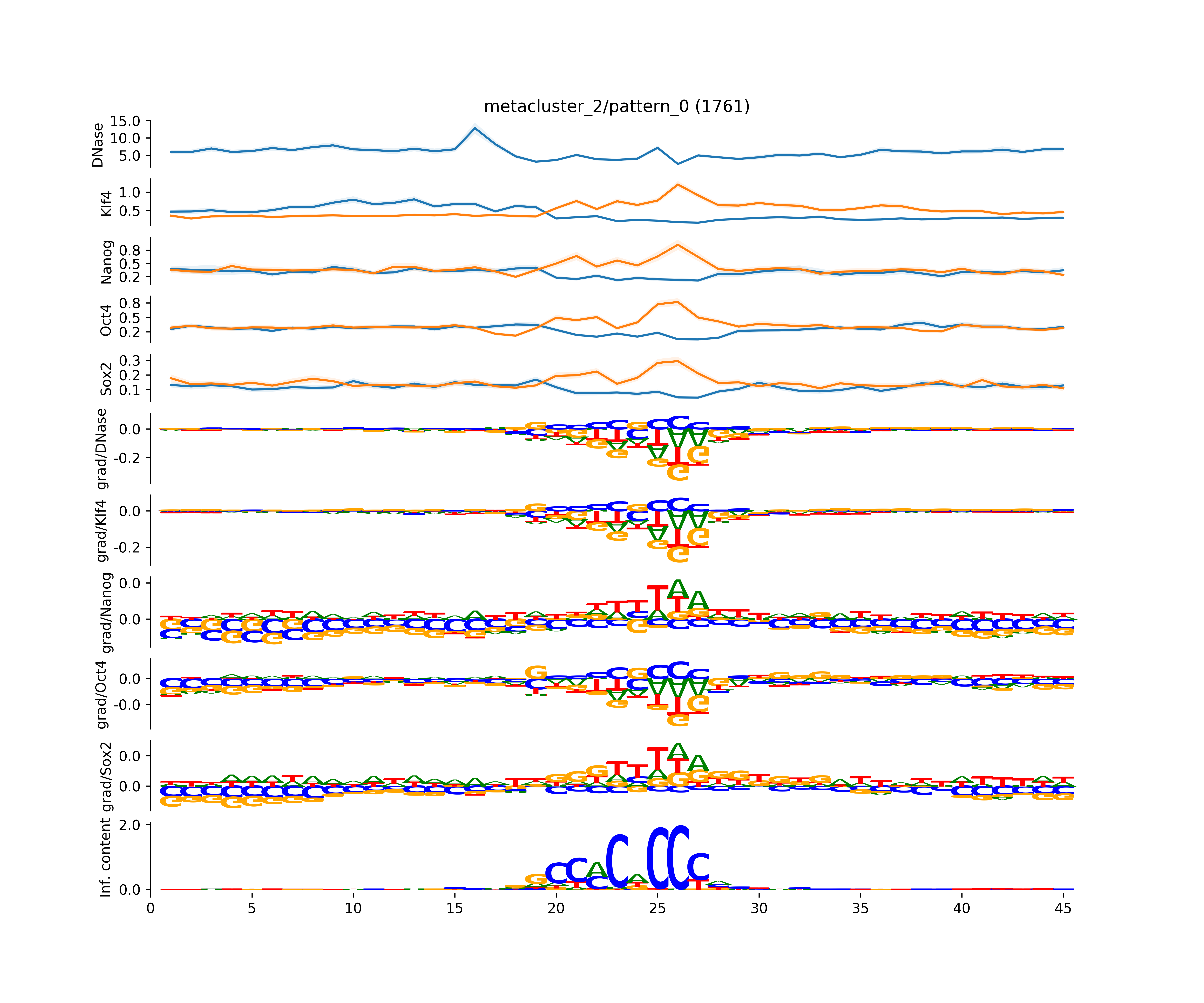
pattern_1: # seqlets: 448

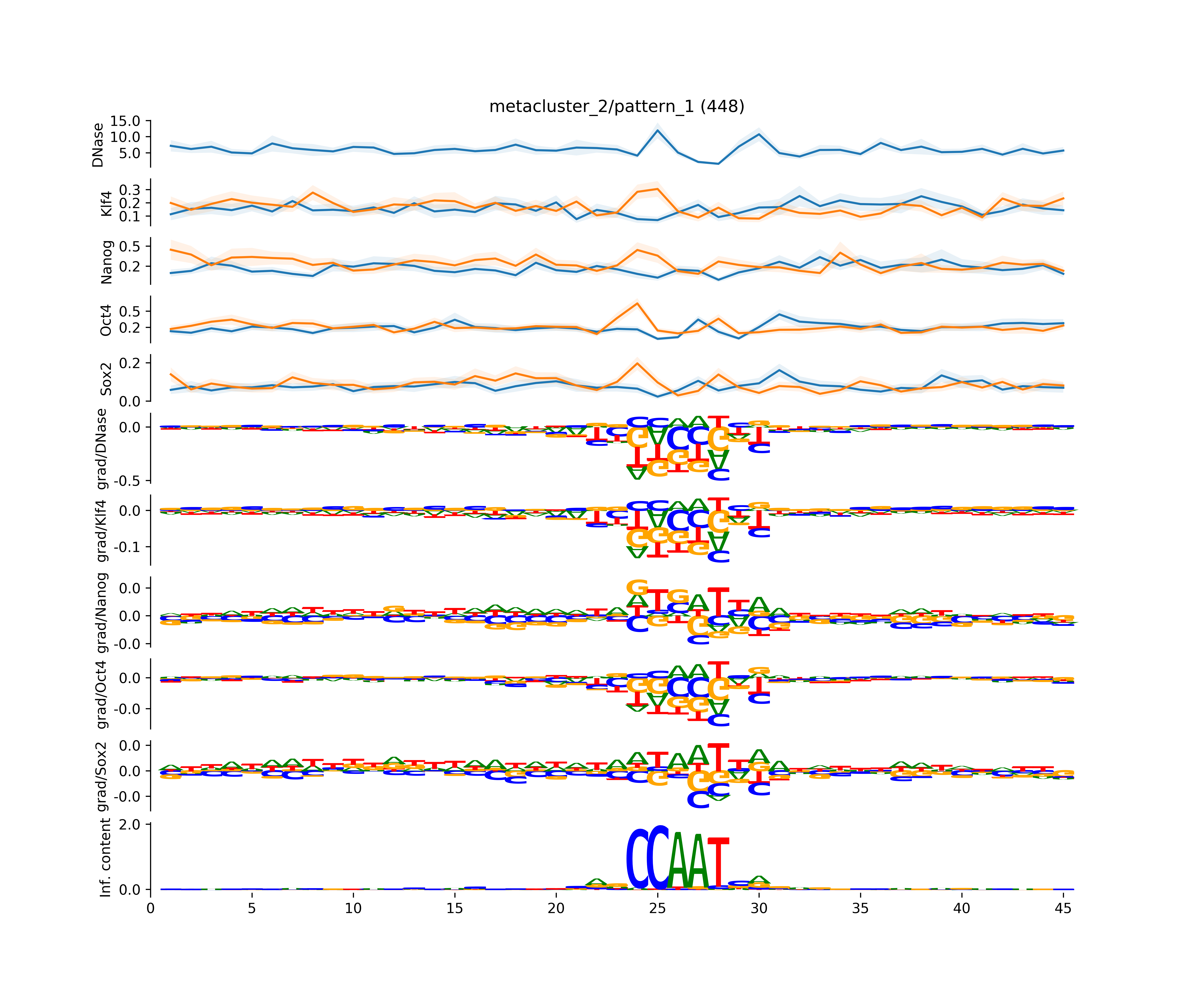
pattern_2: # seqlets: 249

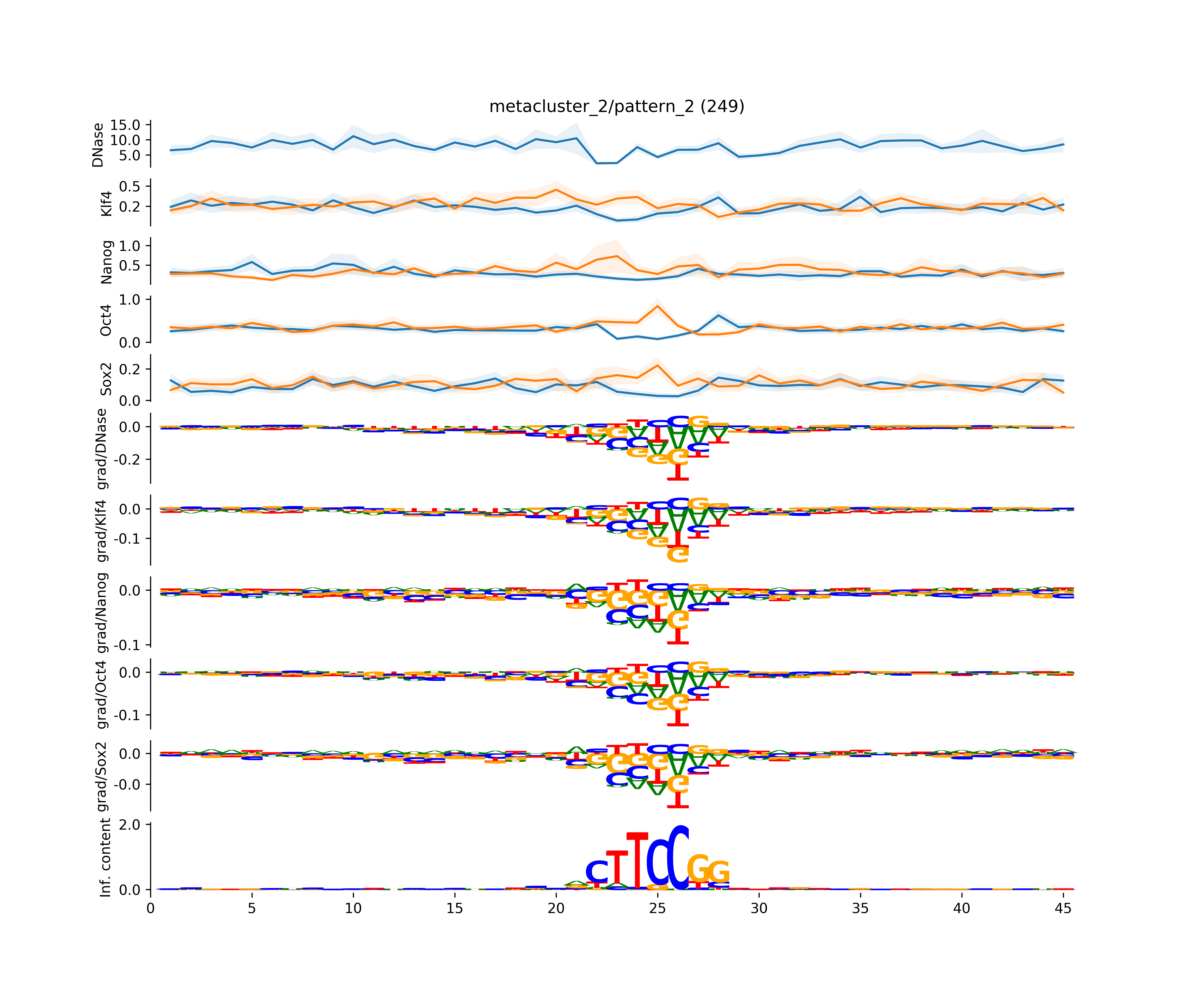
pattern_3: # seqlets: 233

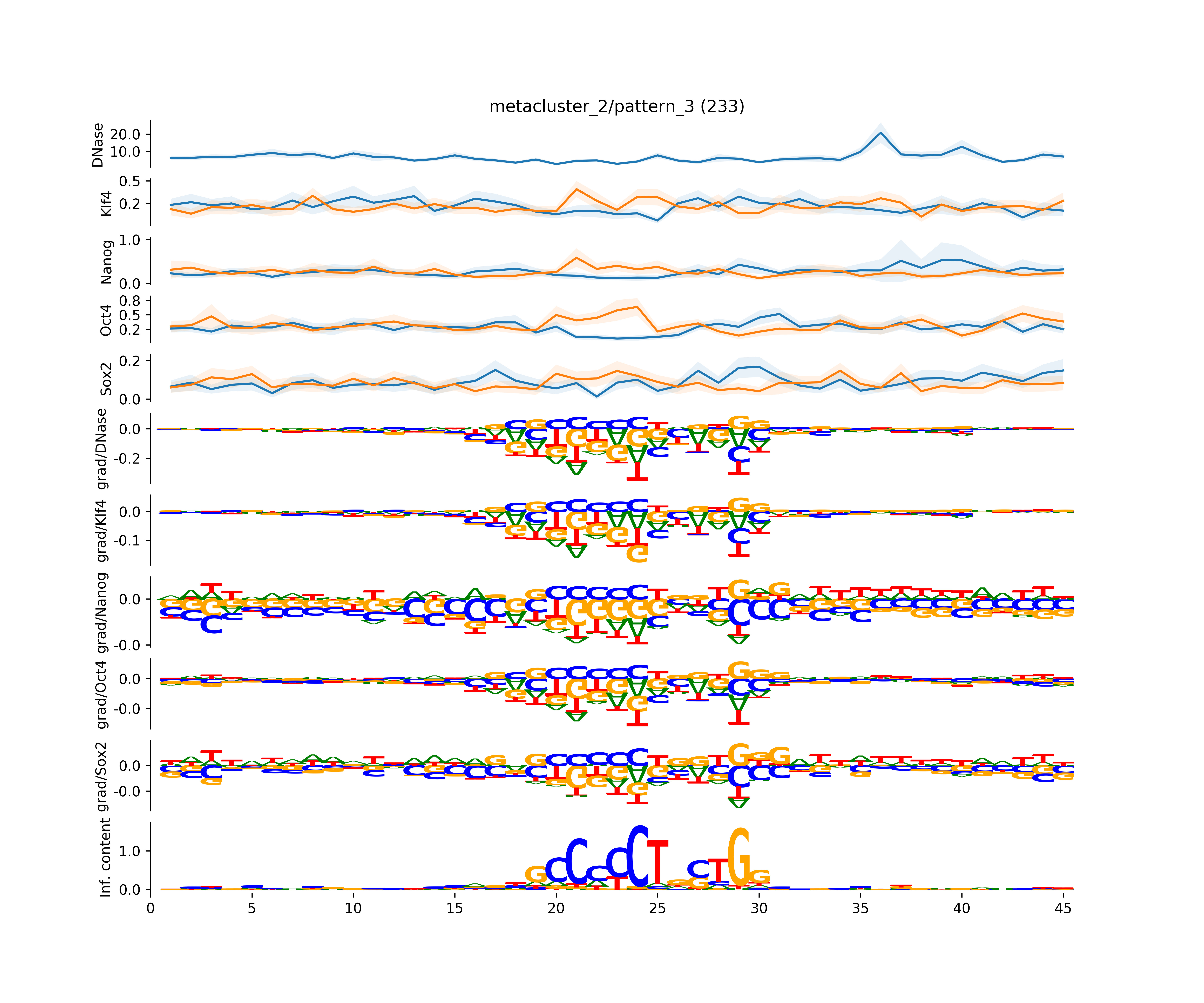
pattern_4: # seqlets: 208

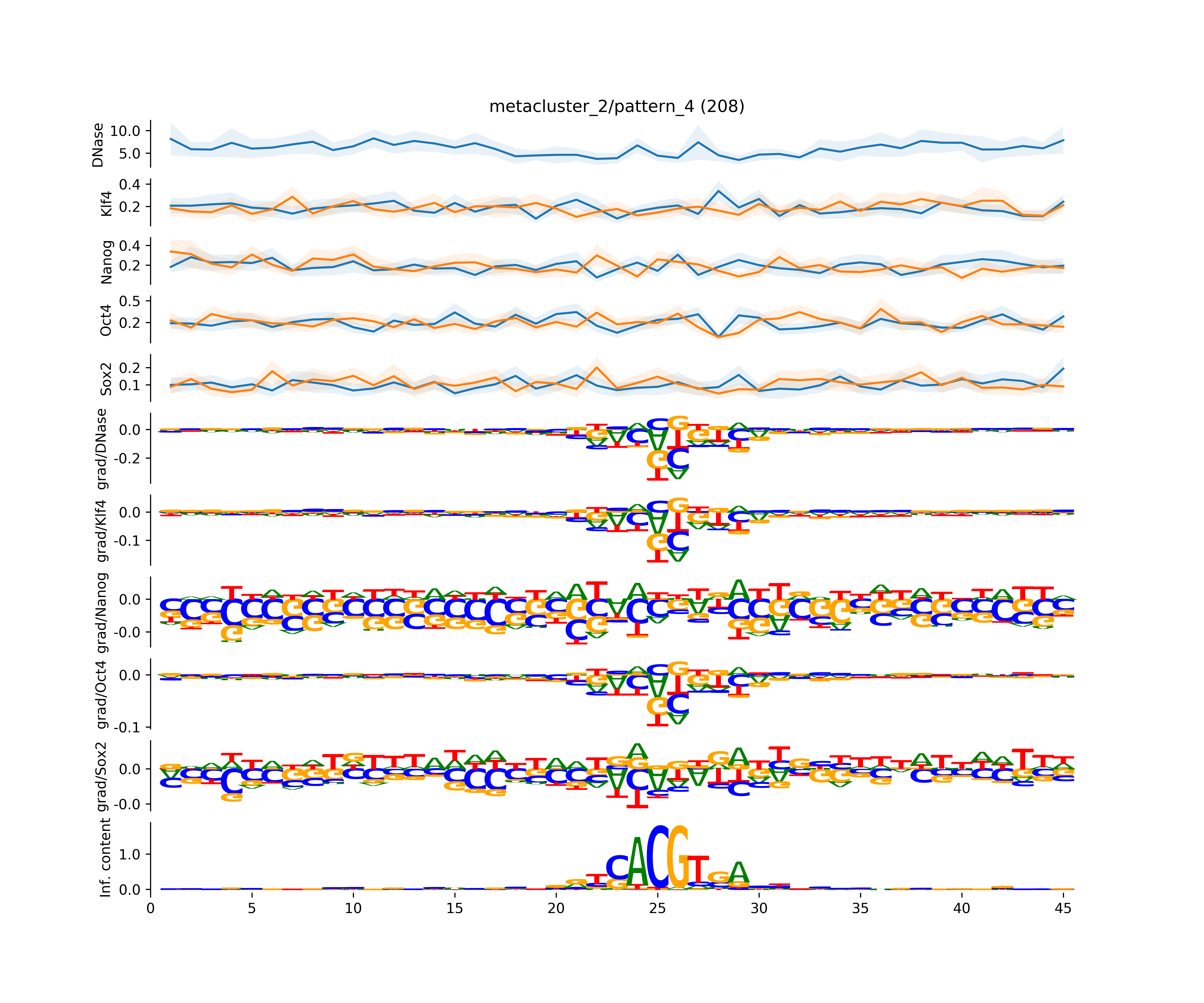
pattern_5: # seqlets: 164

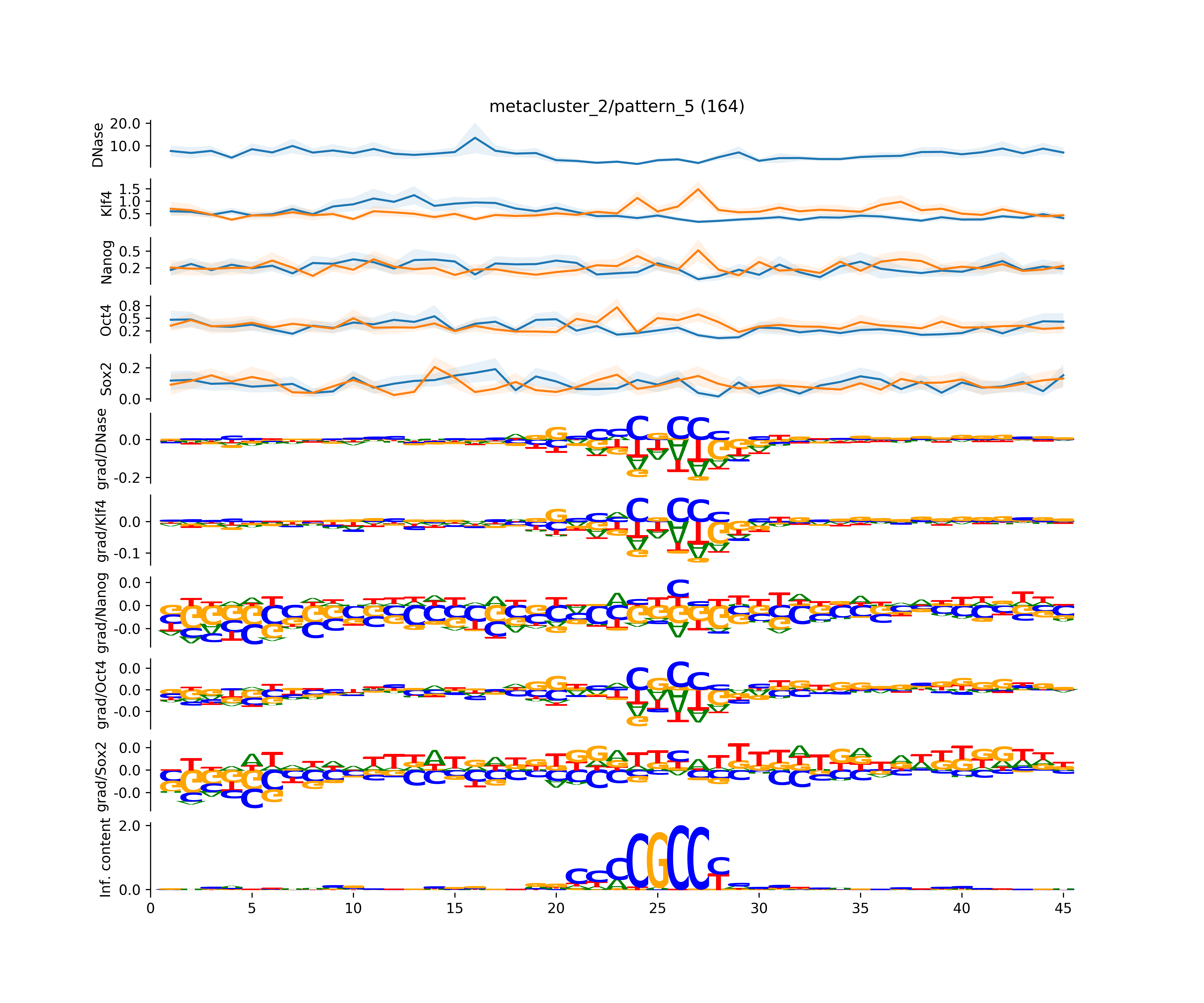
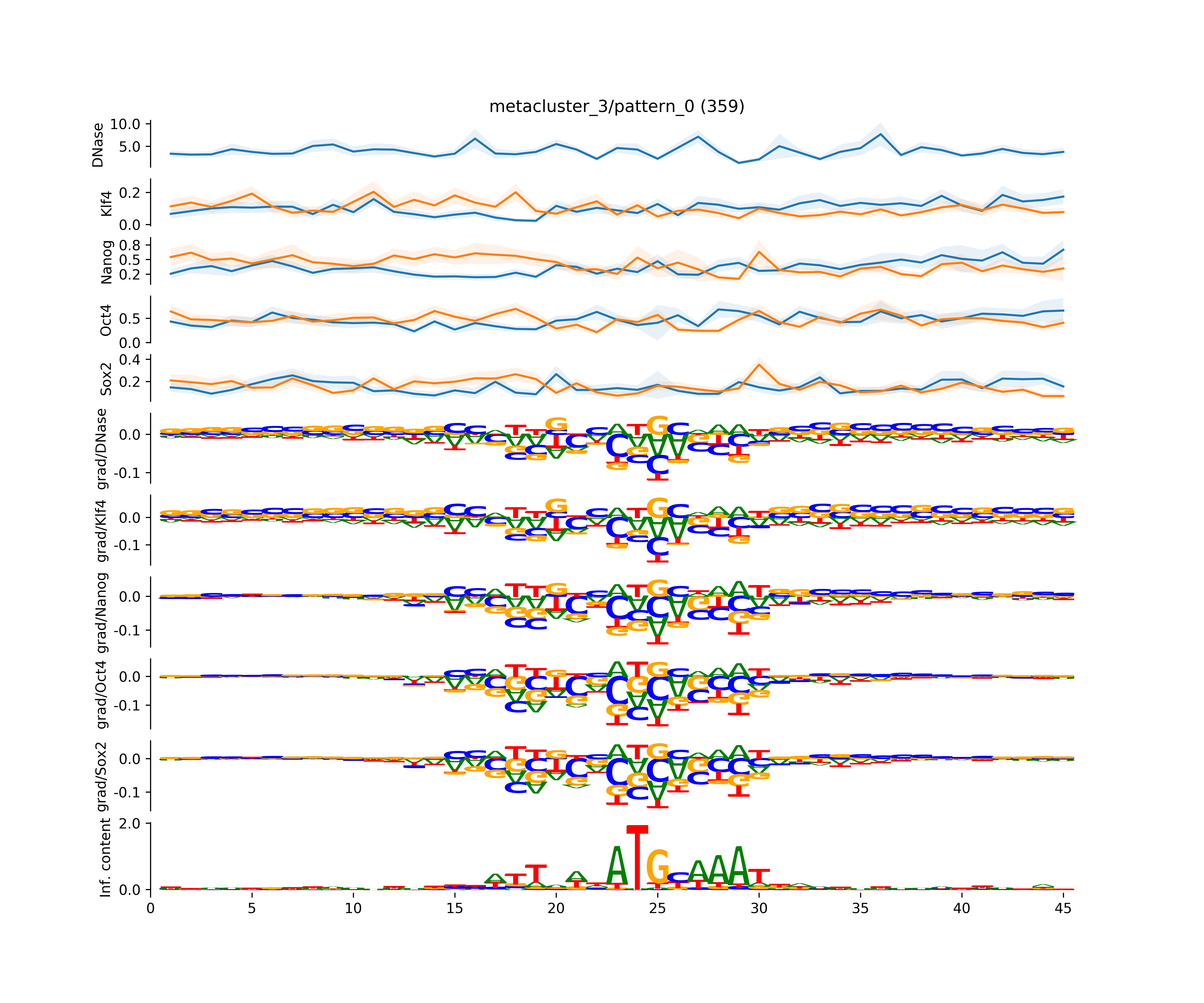
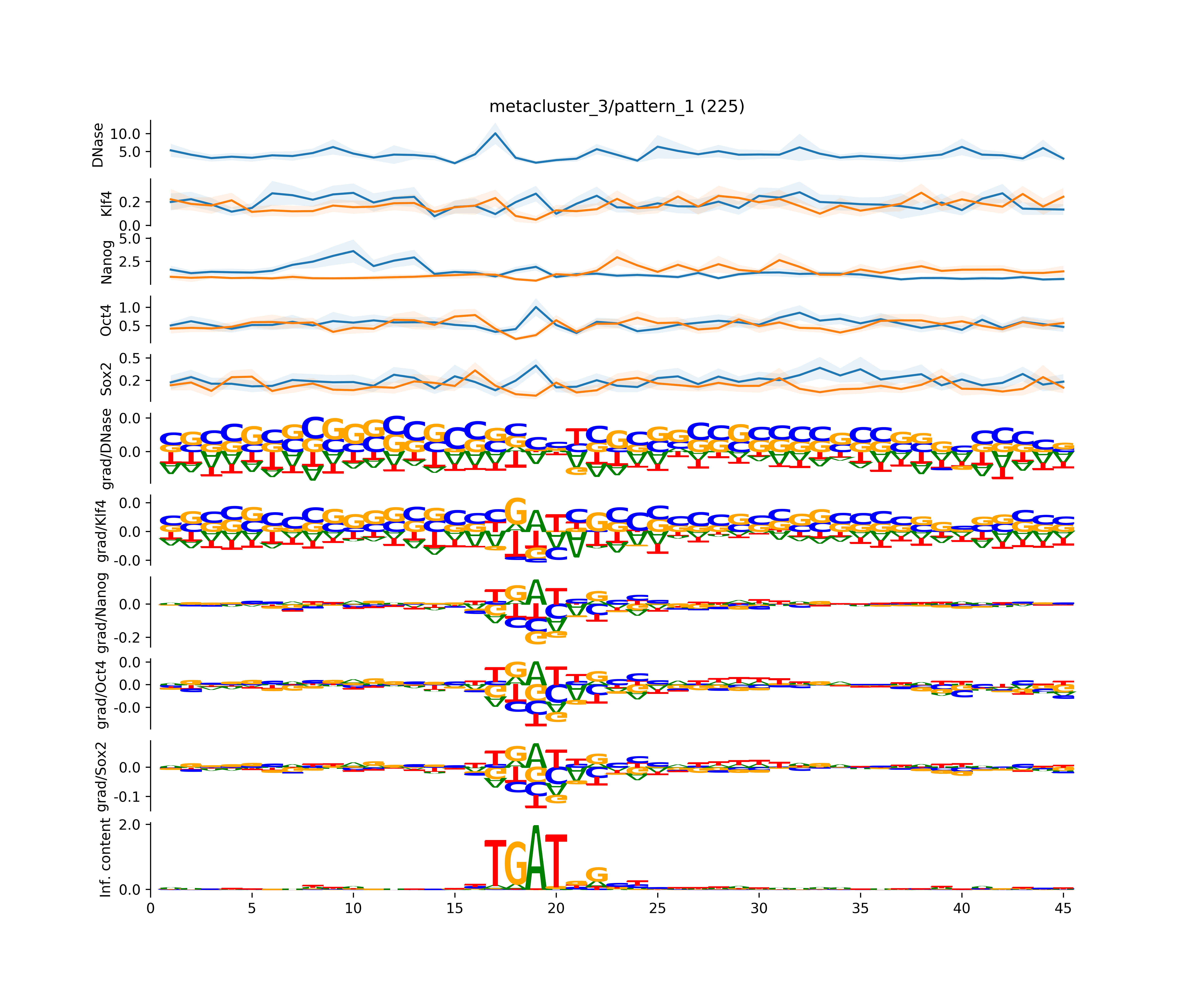
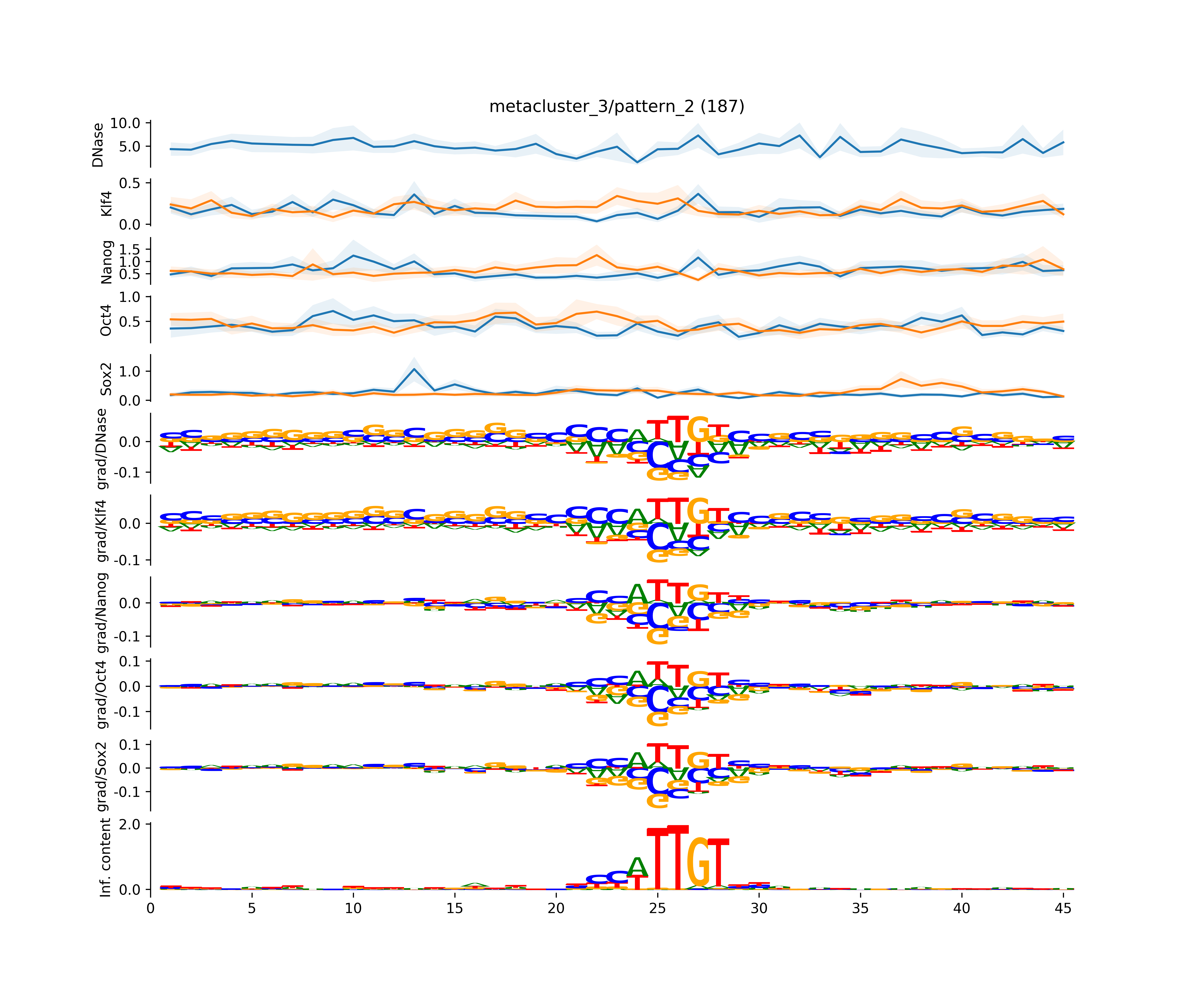
metacluster_3, # patterns: 8, # seqlets: 1318, important for: Nanog,Oct4,Sox2
pattern_0: # seqlets: 359

pattern_1: # seqlets: 225

pattern_2: # seqlets: 187

pattern_3: # seqlets: 98

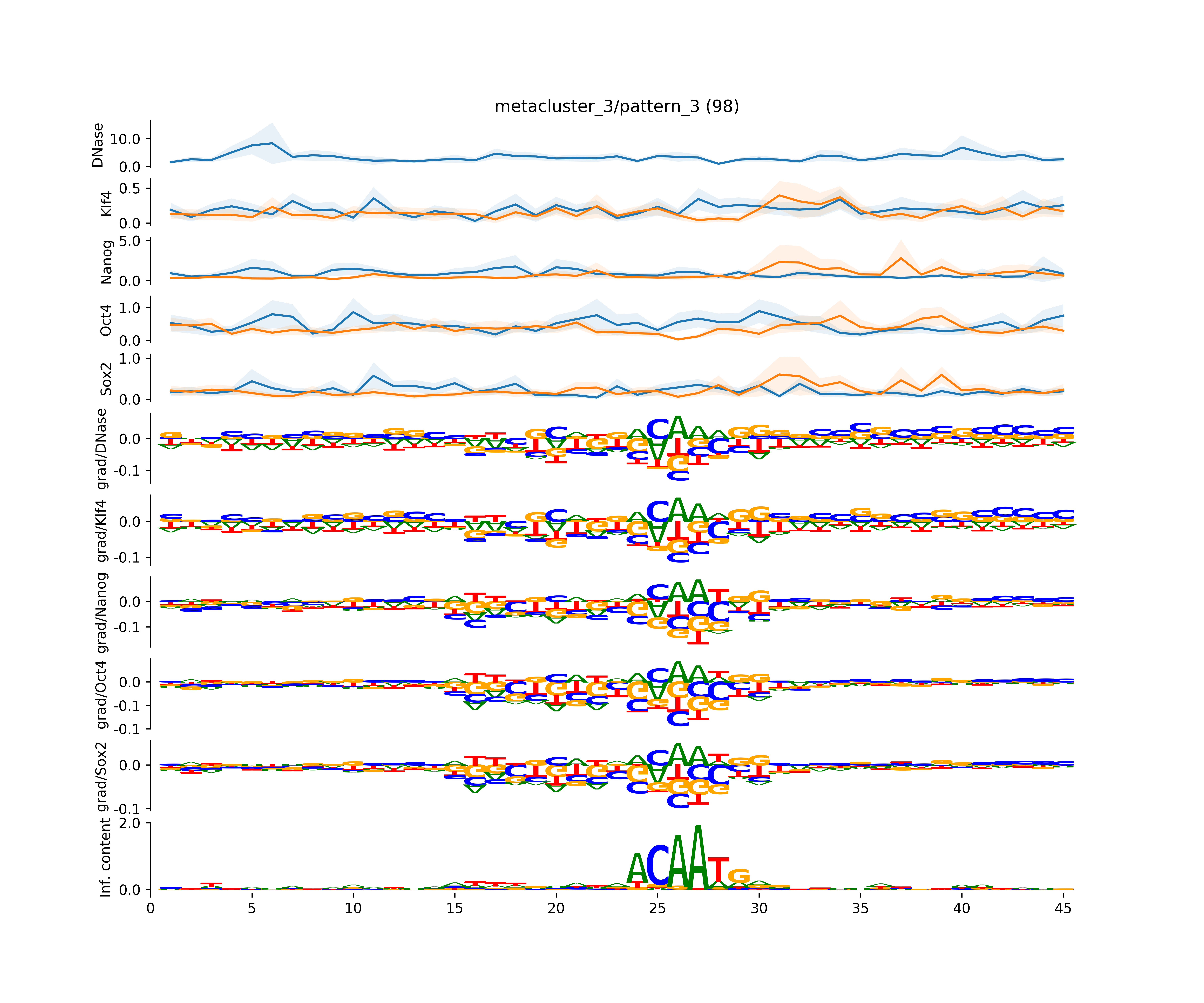
pattern_4: # seqlets: 147

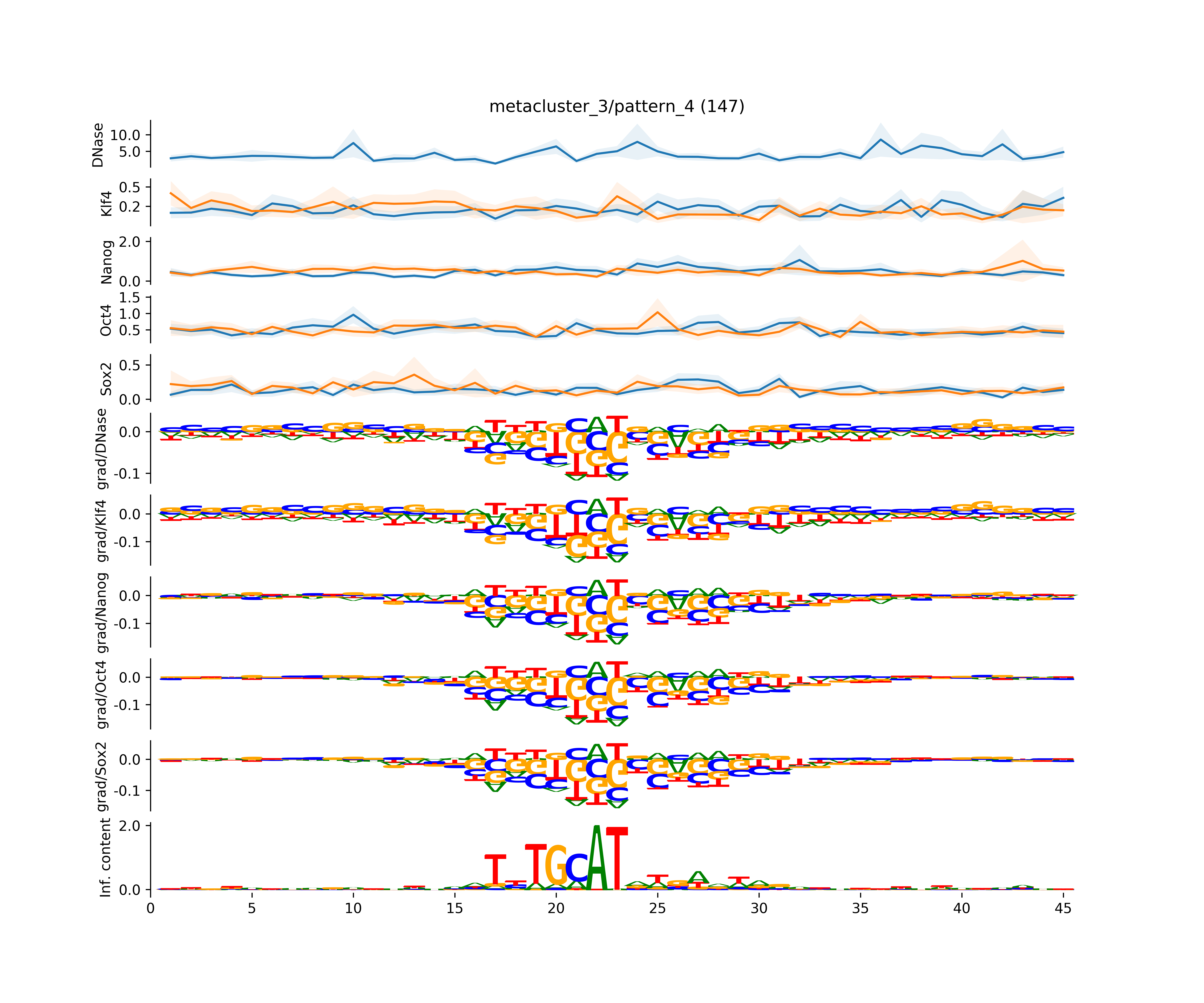
pattern_5: # seqlets: 132

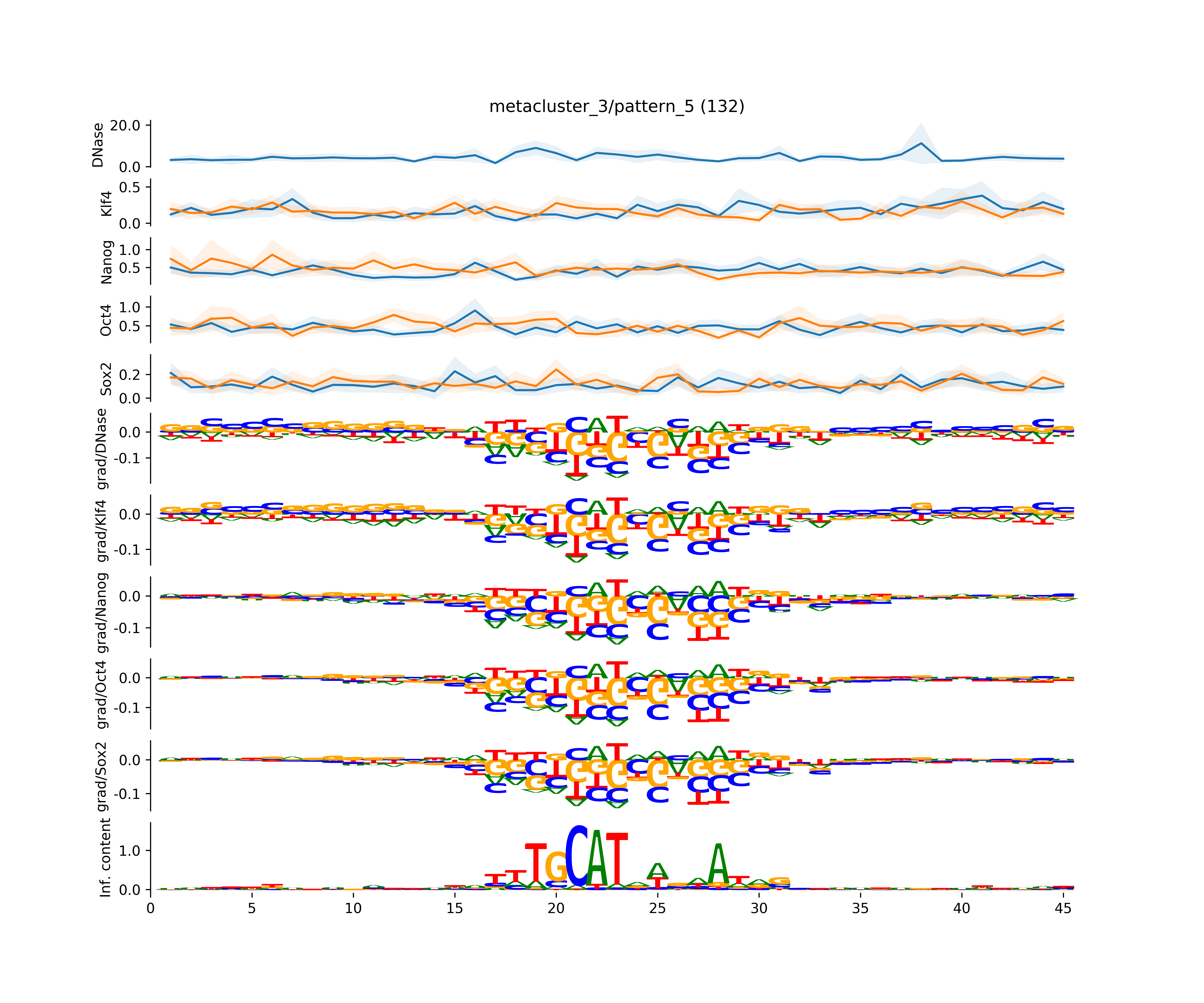
pattern_6: # seqlets: 106

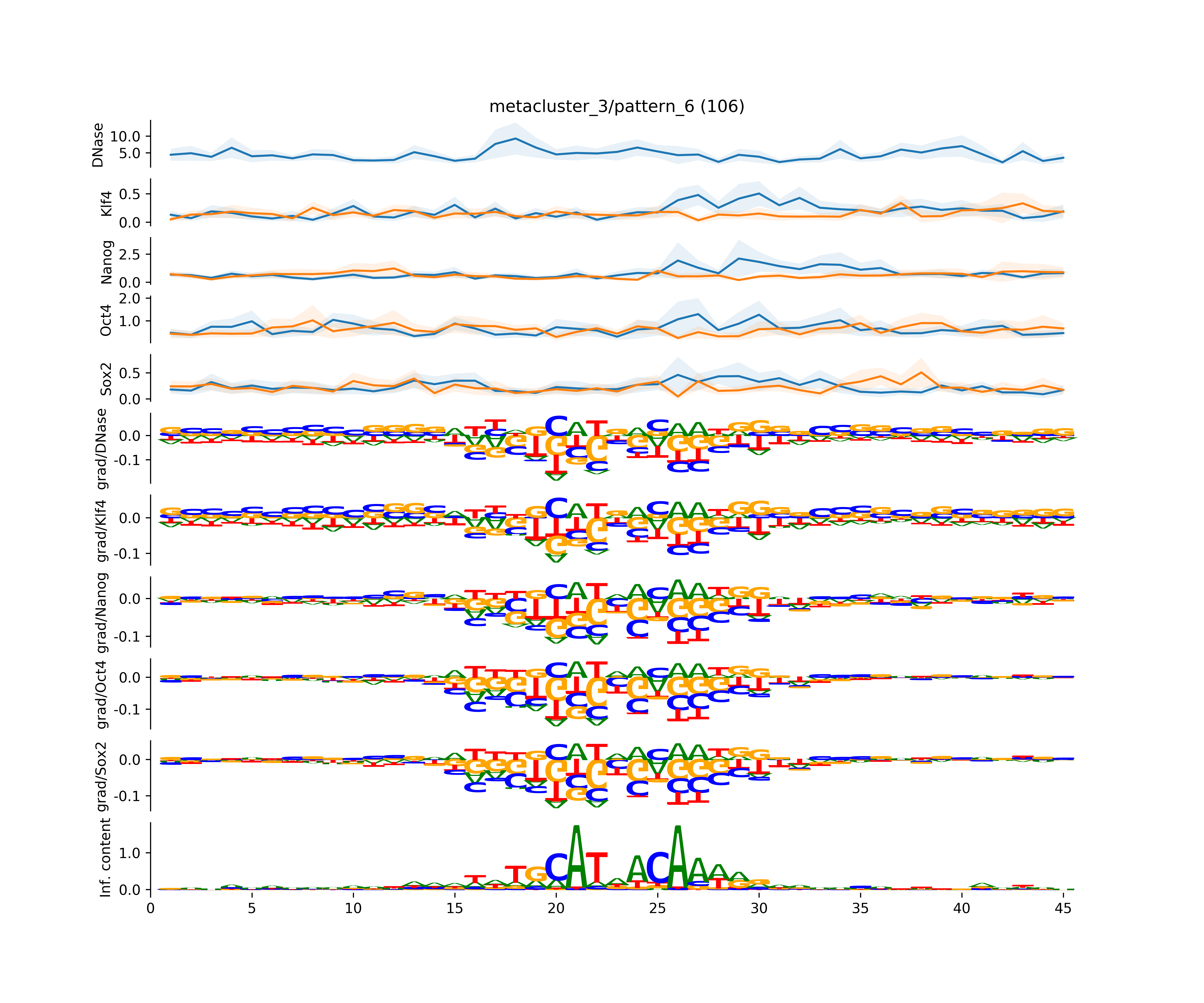
pattern_7: # seqlets: 64

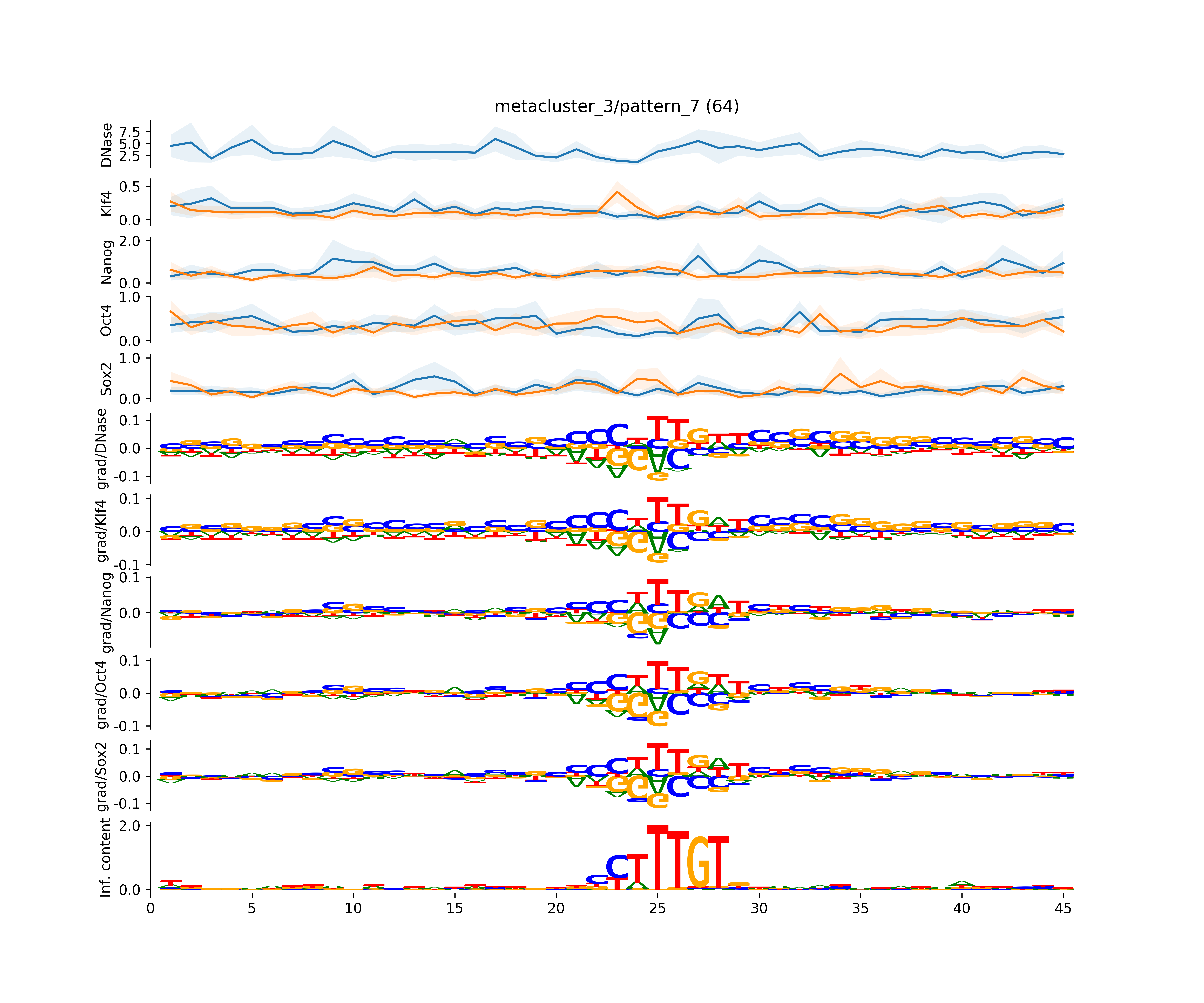
metacluster_4, # patterns: 7, # seqlets: 1049, important for: Klf4,Nanog,Oct4,Sox2
pattern_0: # seqlets: 237

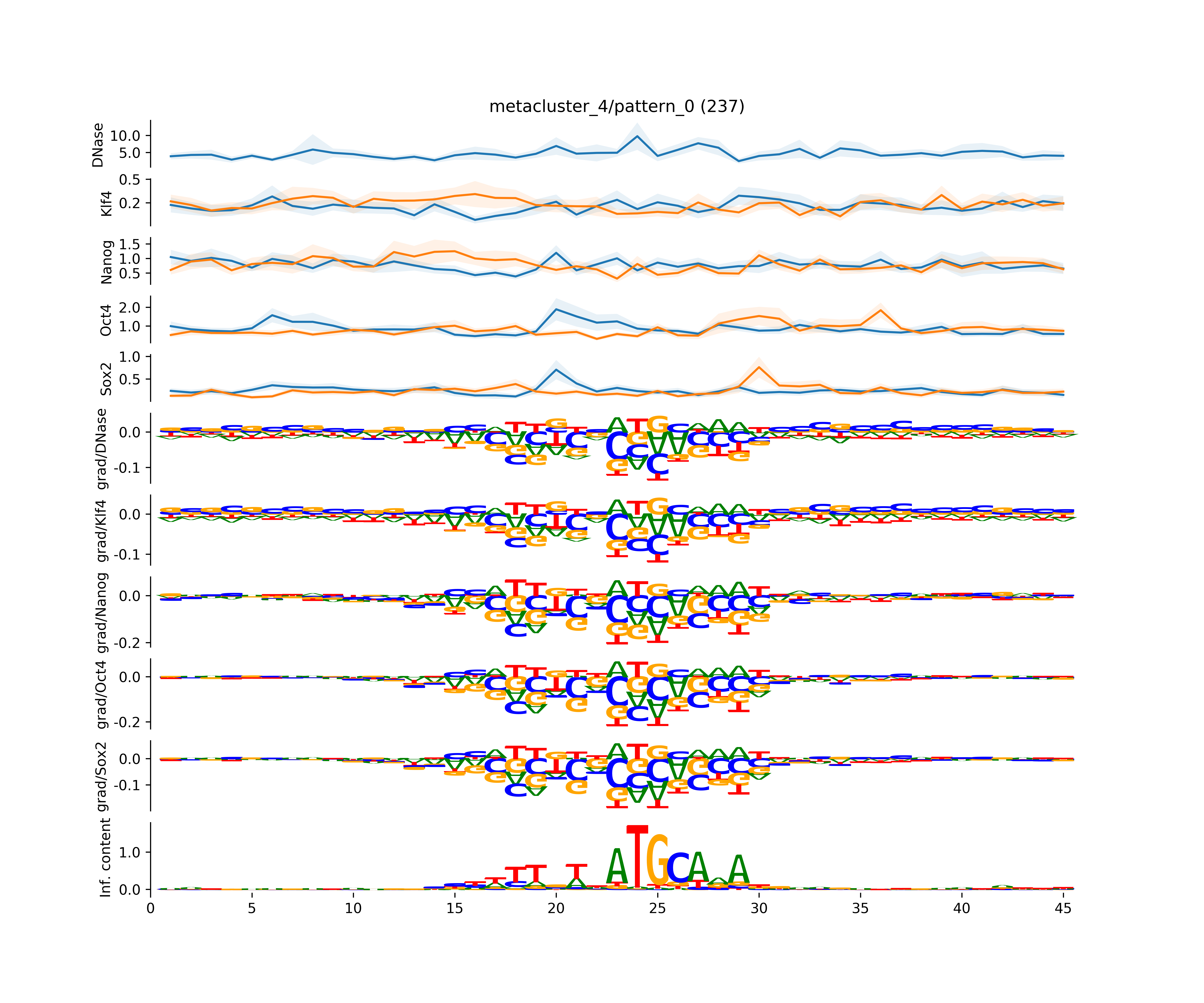
pattern_1: # seqlets: 200

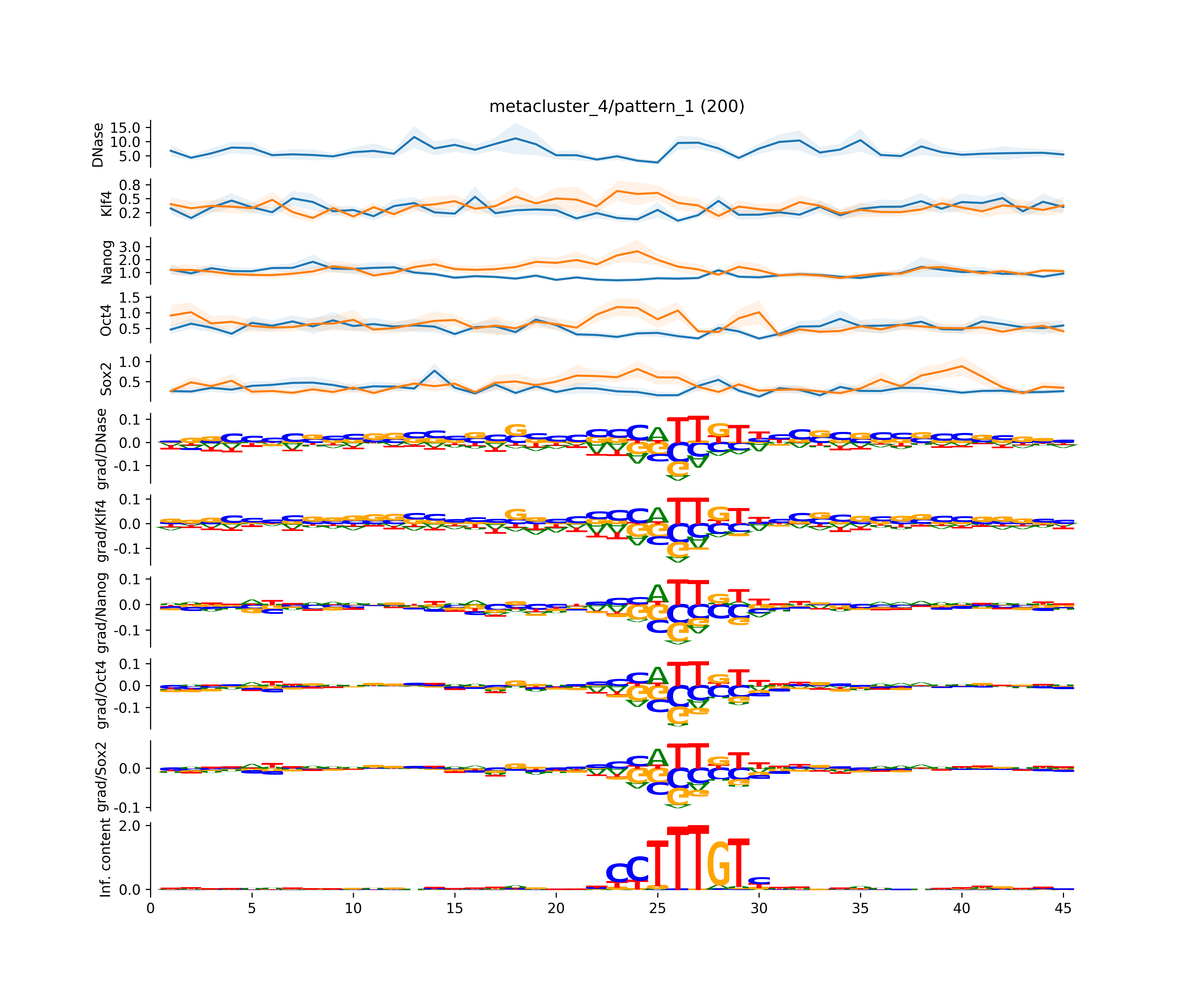
pattern_2: # seqlets: 146

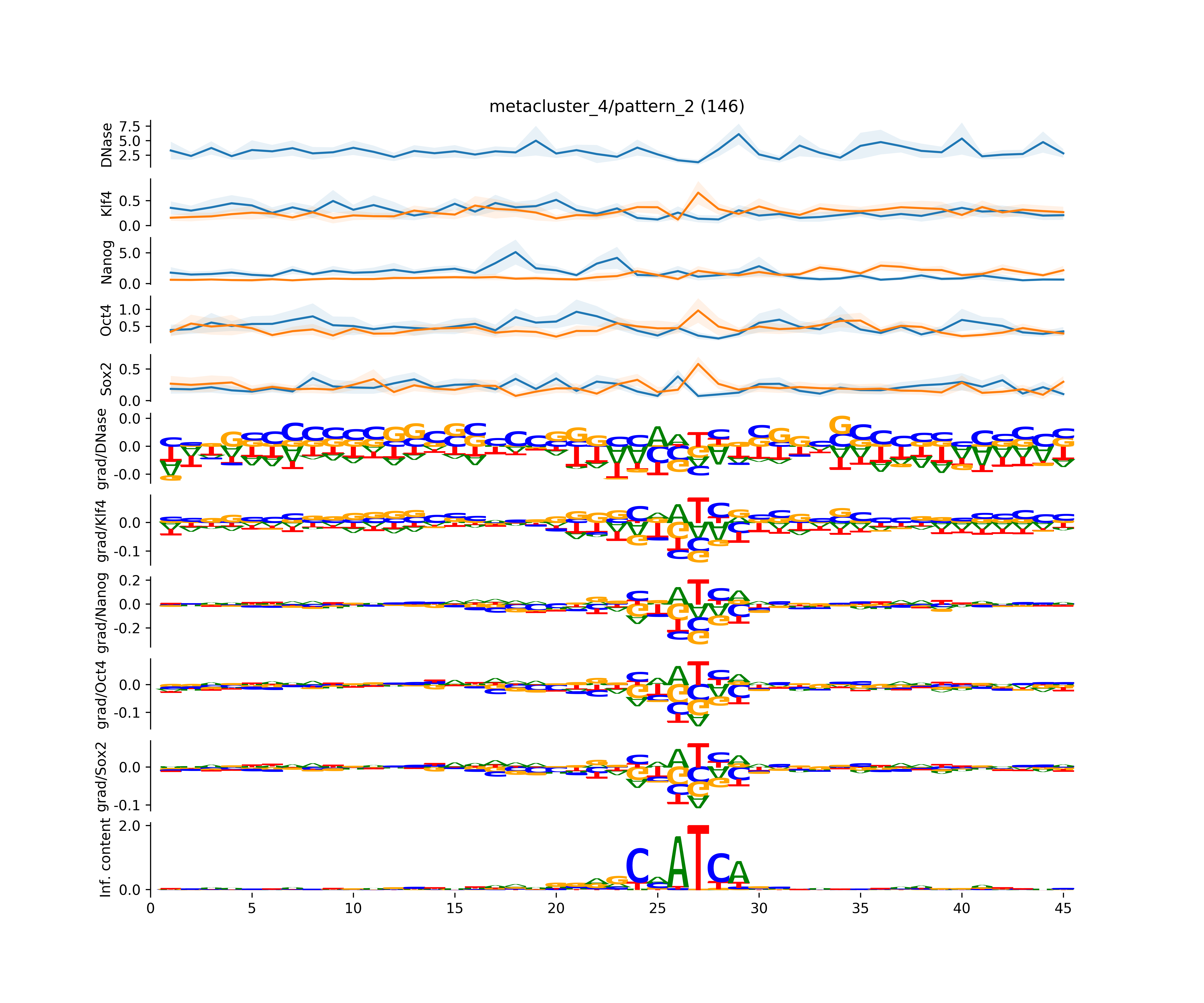
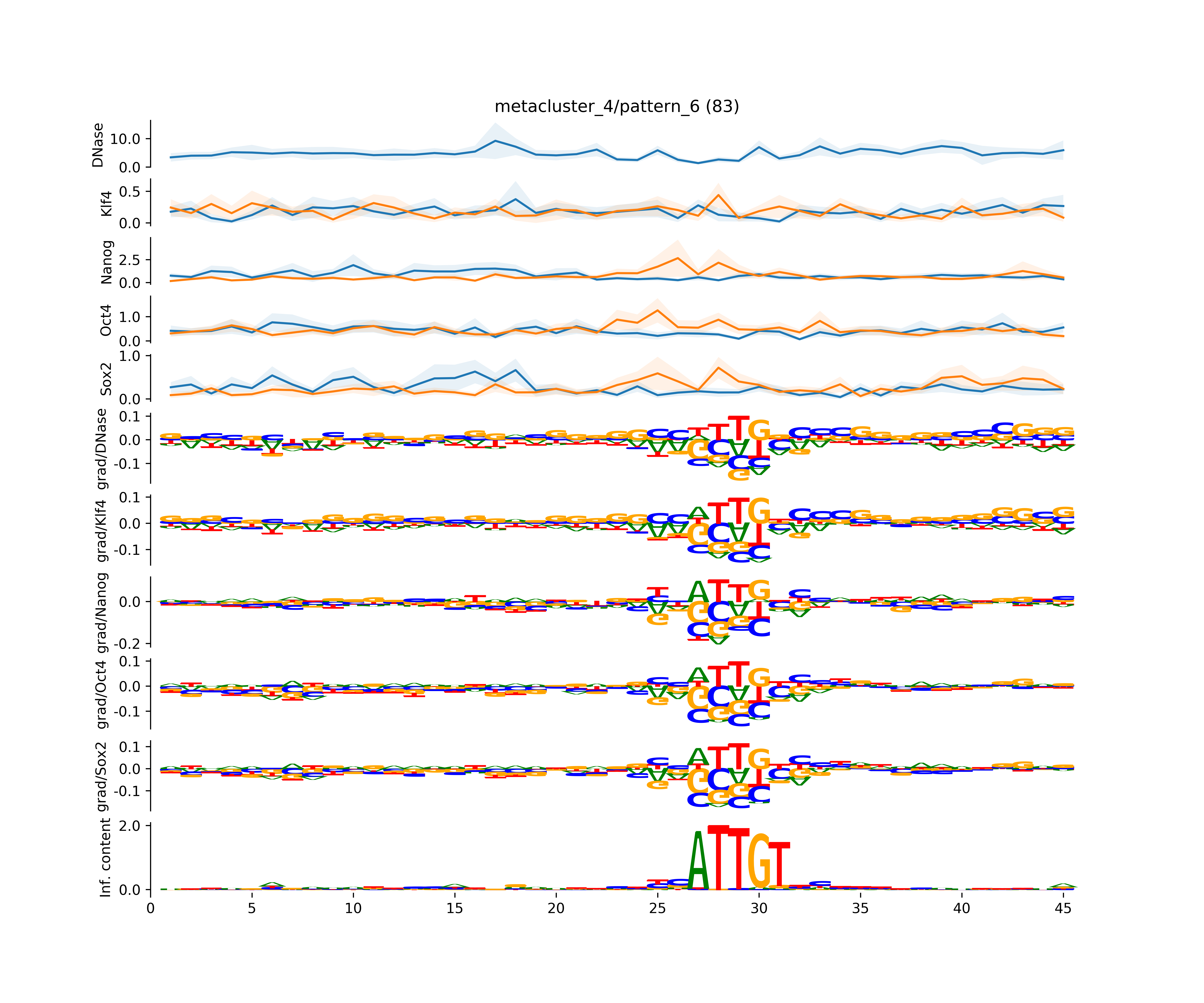
pattern_3: # seqlets: 149

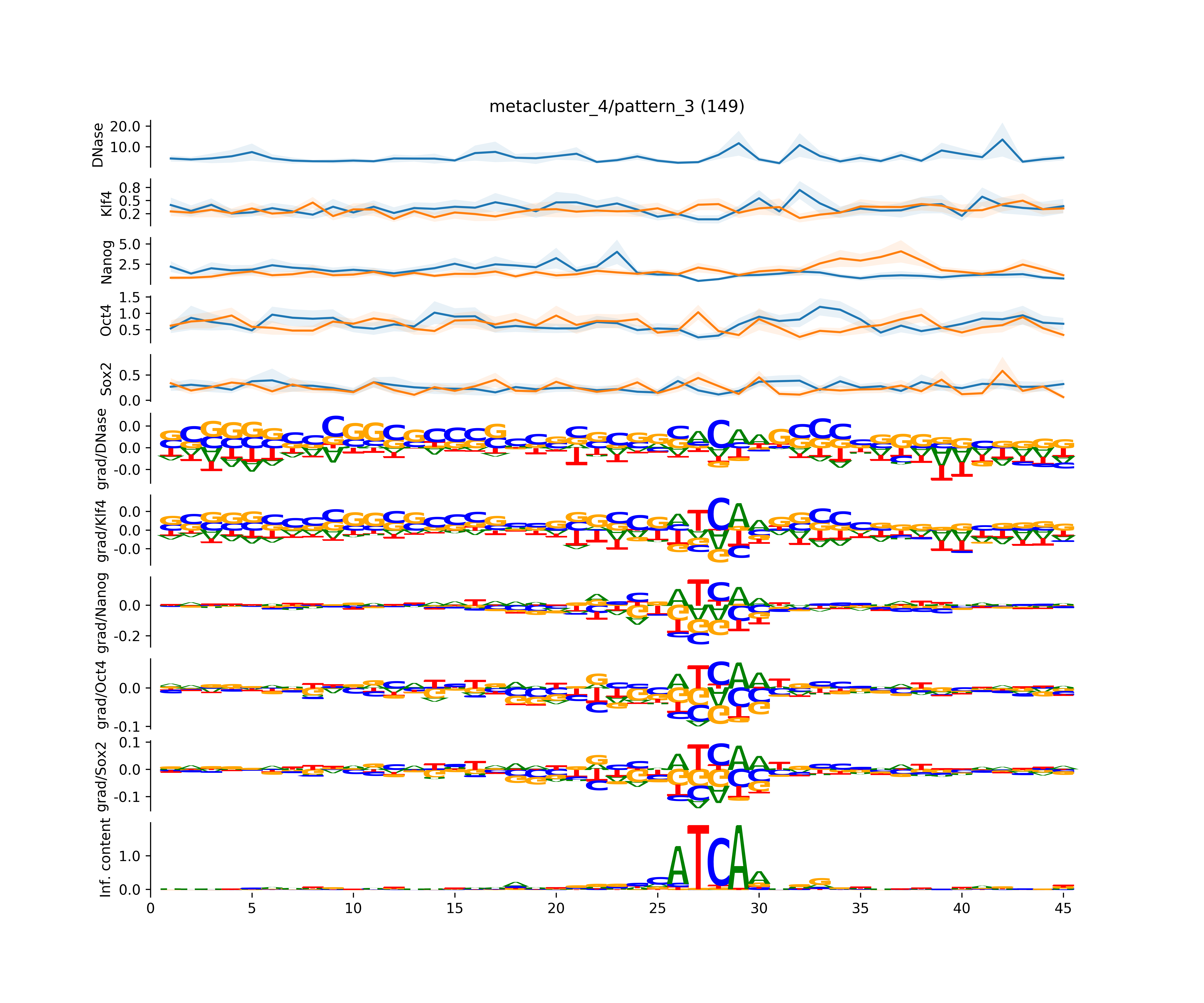
pattern_4: # seqlets: 133

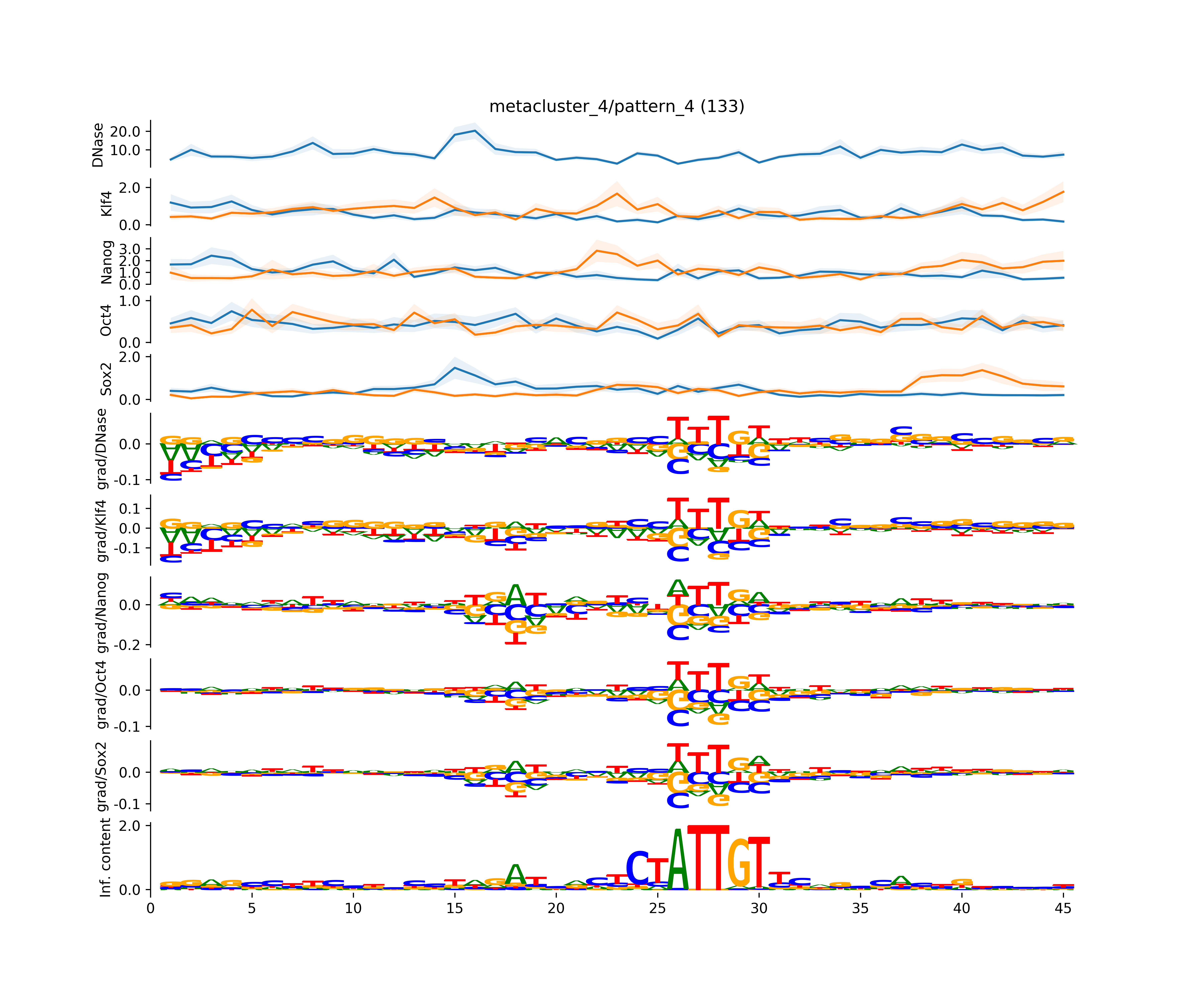
pattern_5: # seqlets: 101

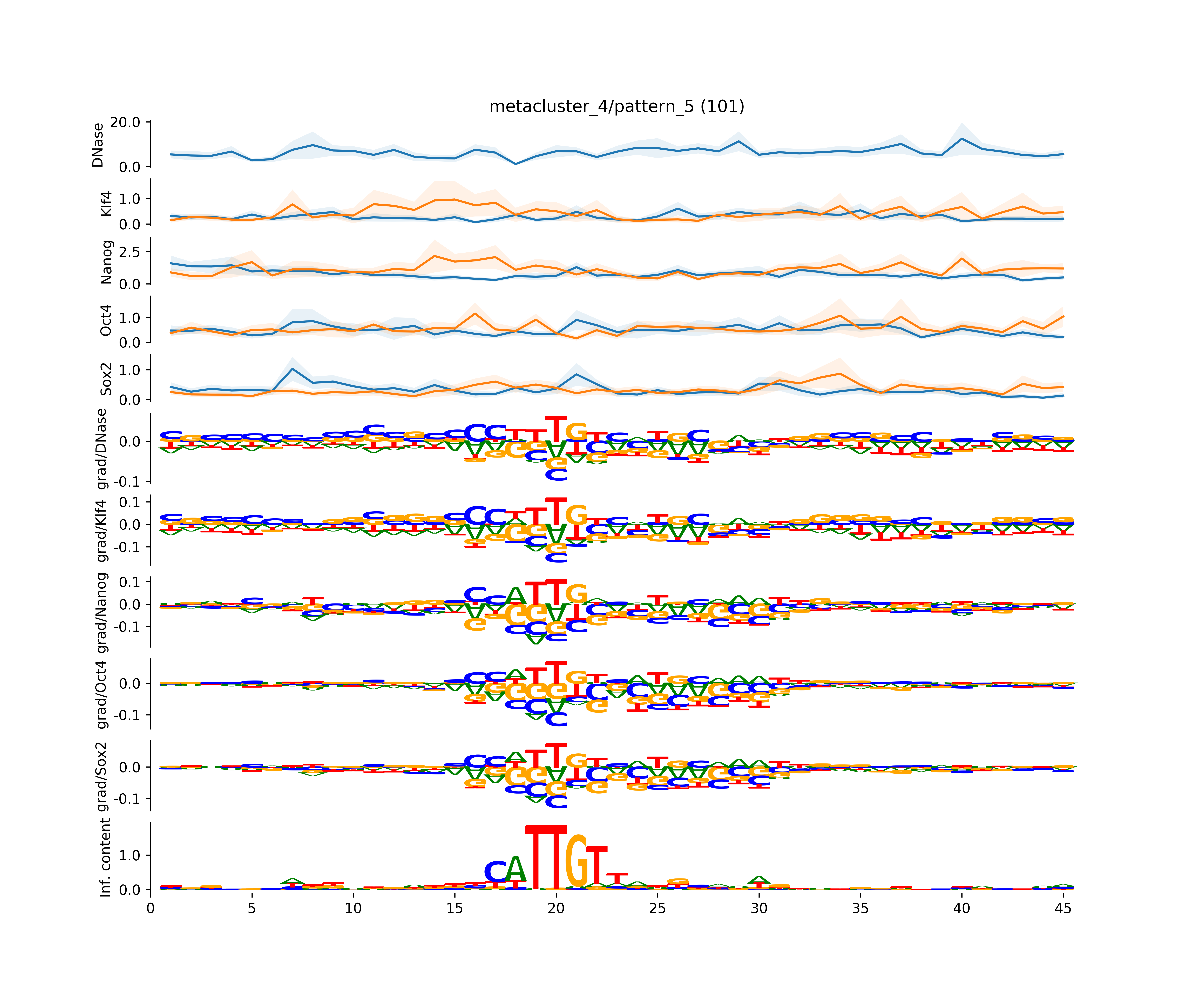
pattern_6: # seqlets: 83

metacluster_5, # patterns: 7, # seqlets: 1477, important for: DNase
pattern_0: # seqlets: 487

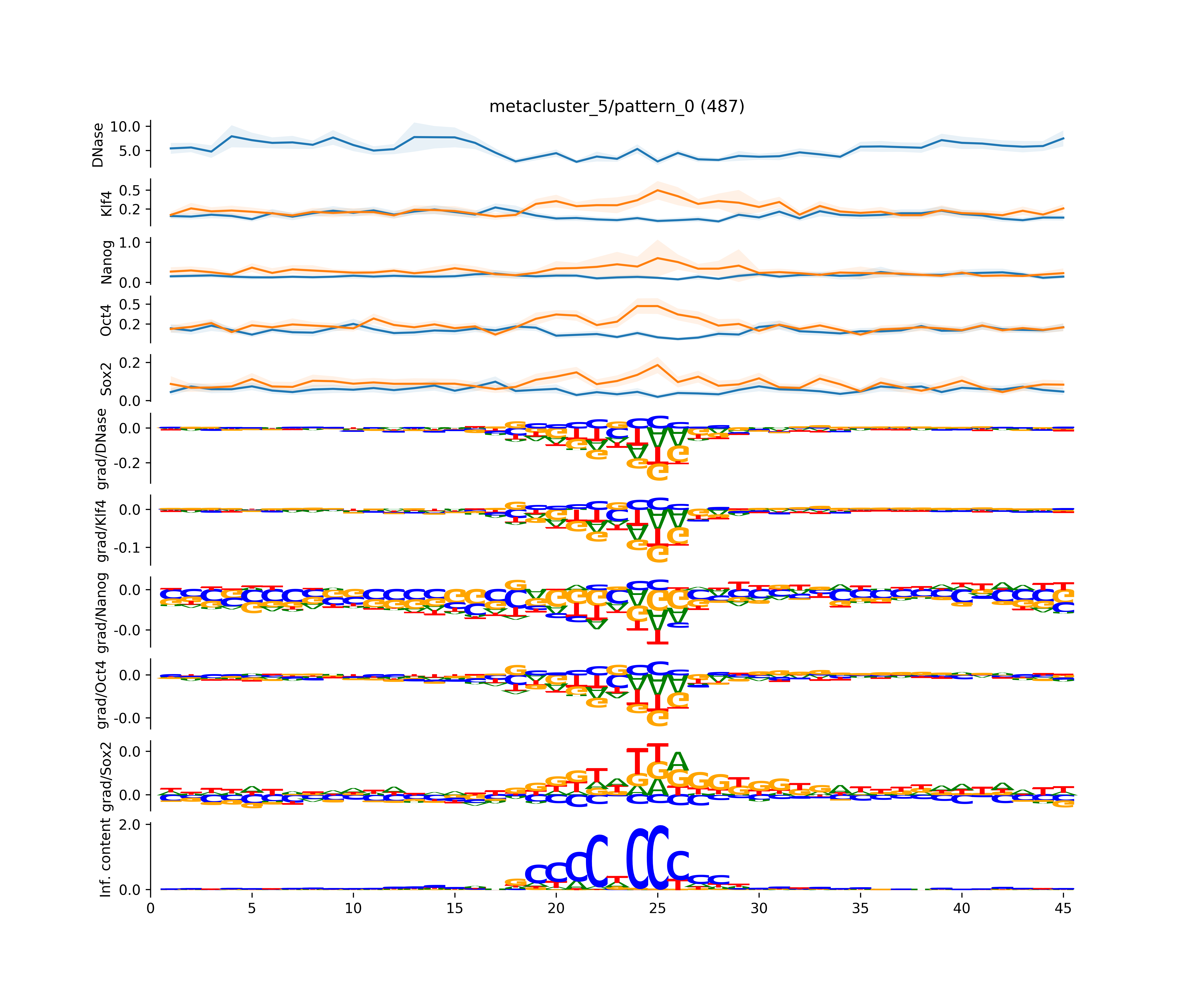
pattern_1: # seqlets: 375

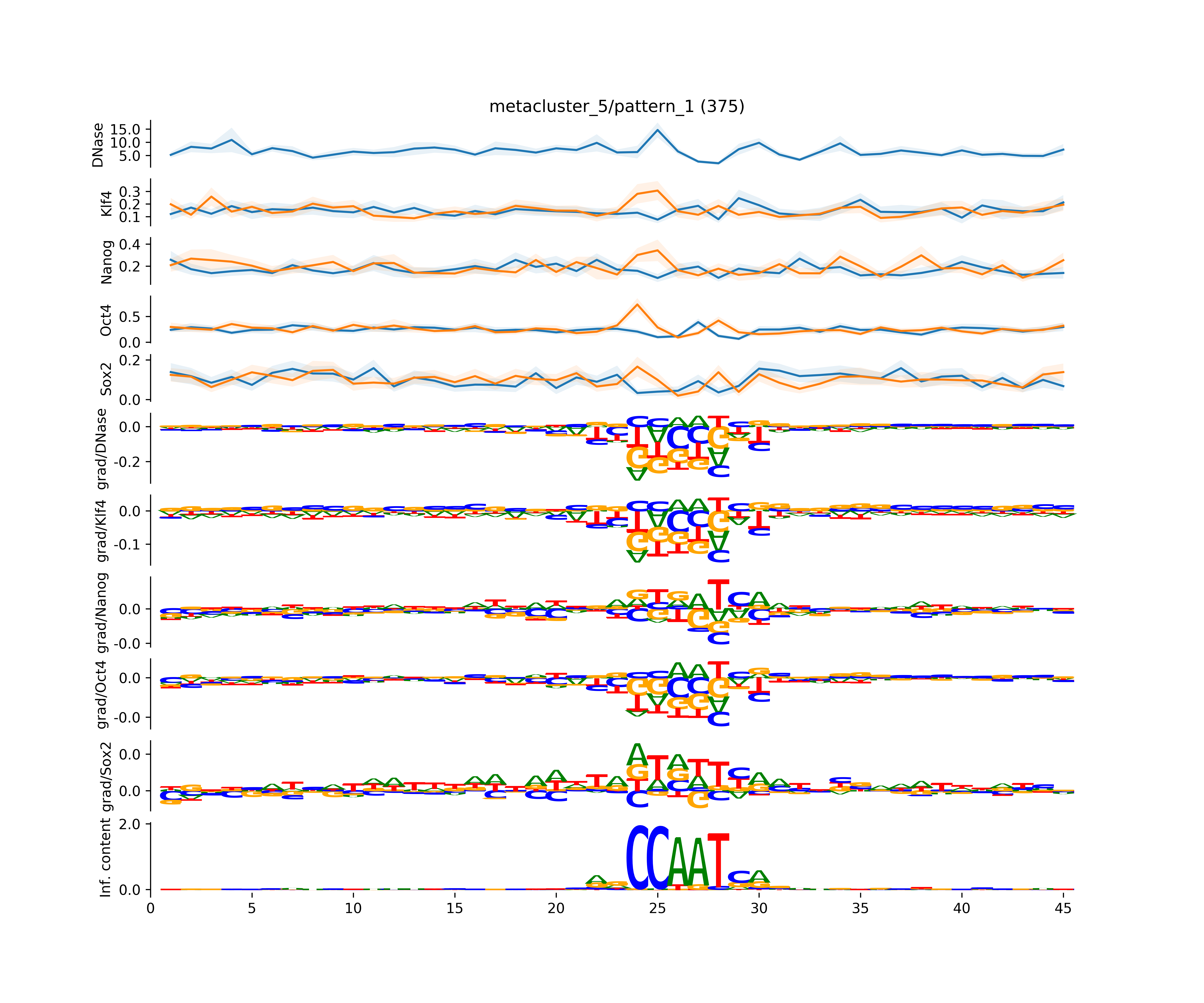
pattern_2: # seqlets: 239

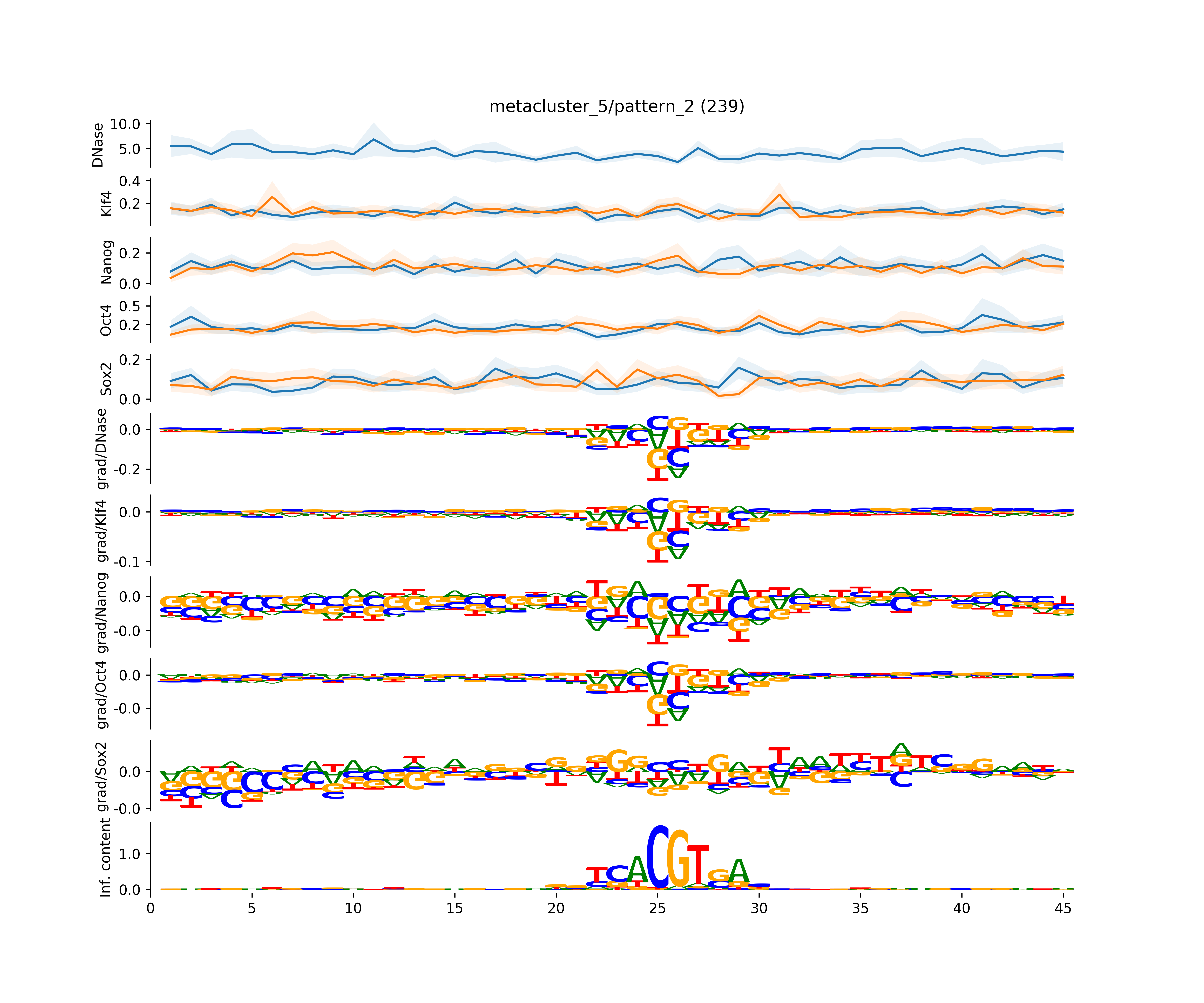
pattern_3: # seqlets: 101

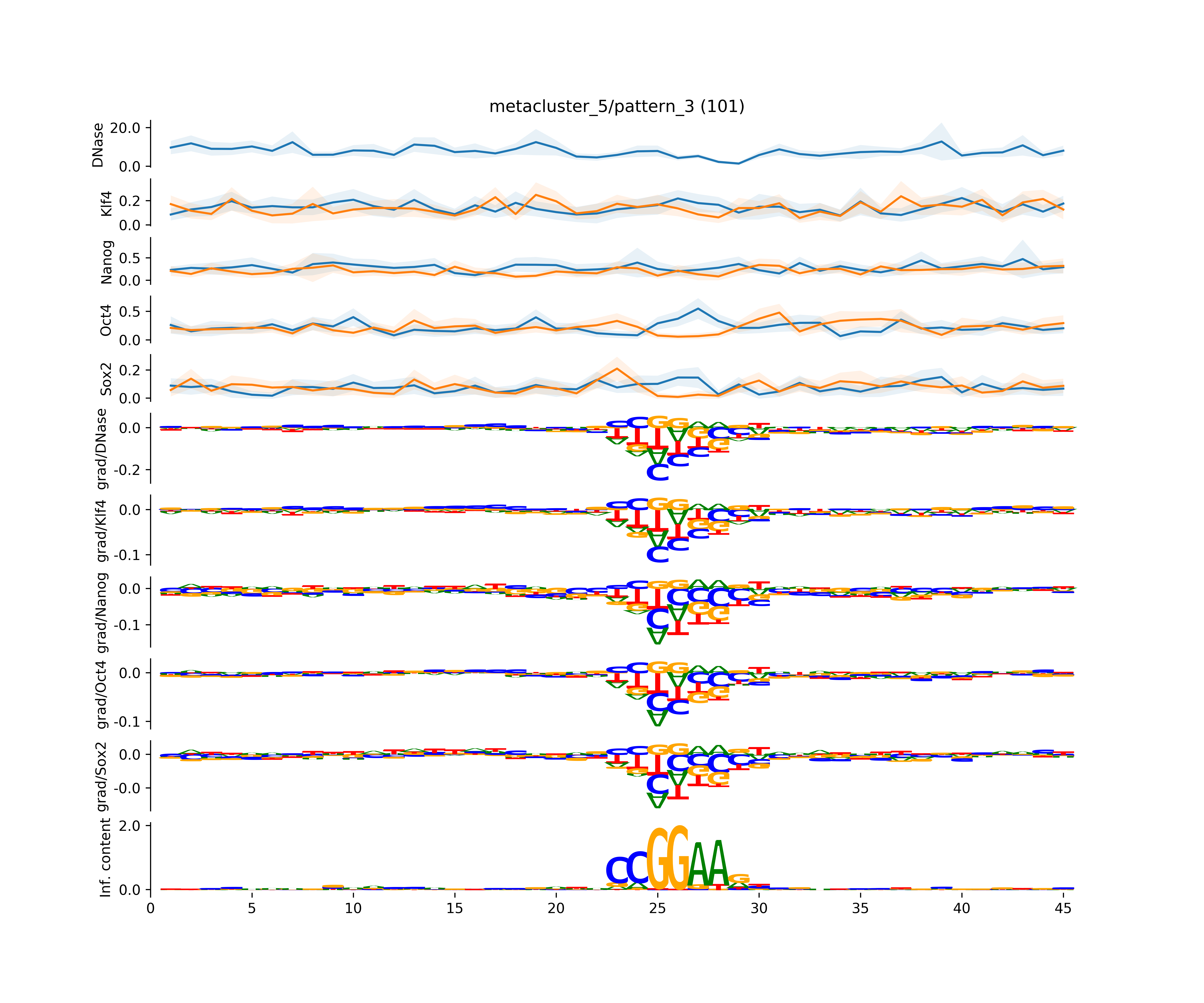
pattern_4: # seqlets: 96

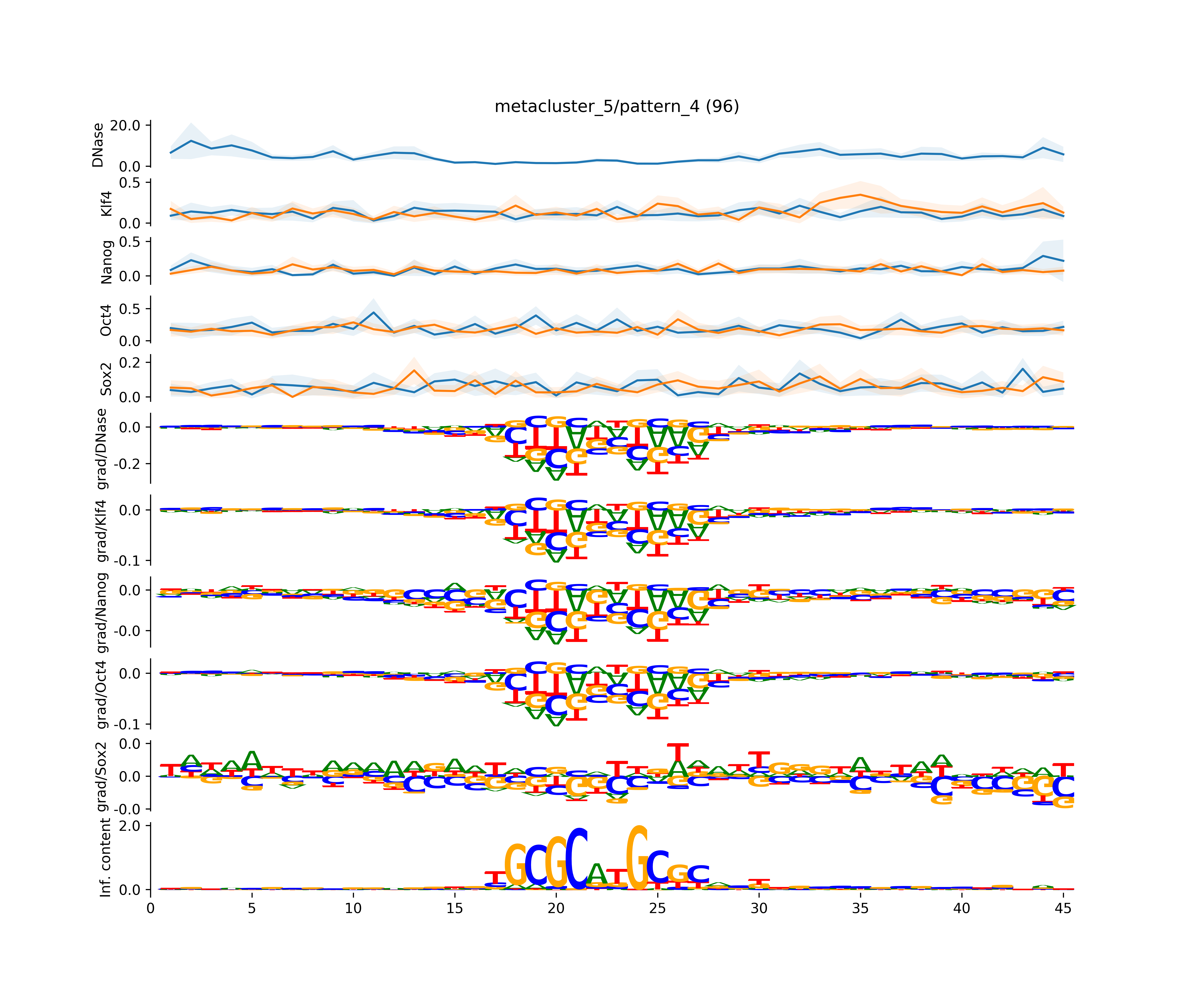
pattern_5: # seqlets: 98

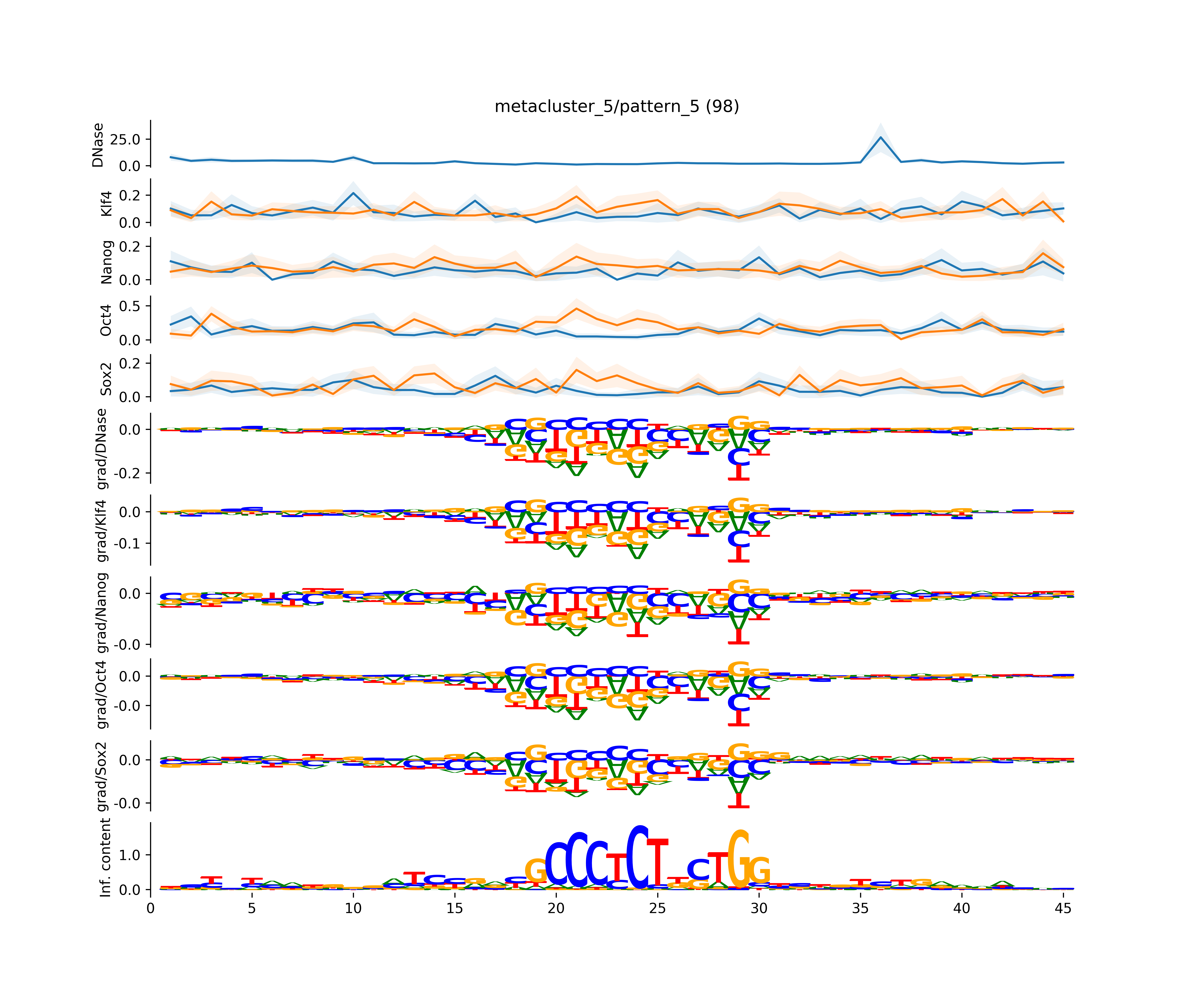
pattern_6: # seqlets: 81

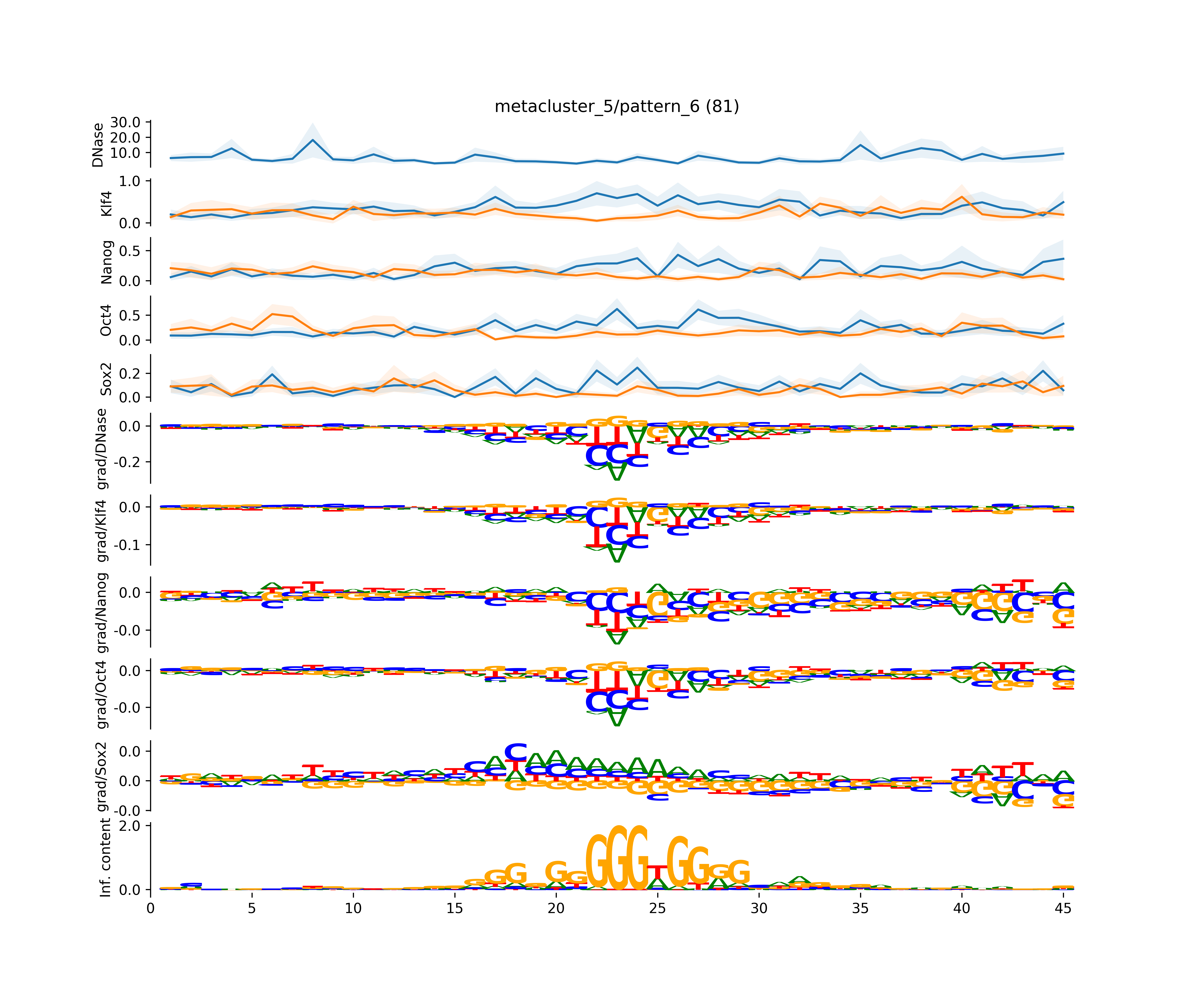
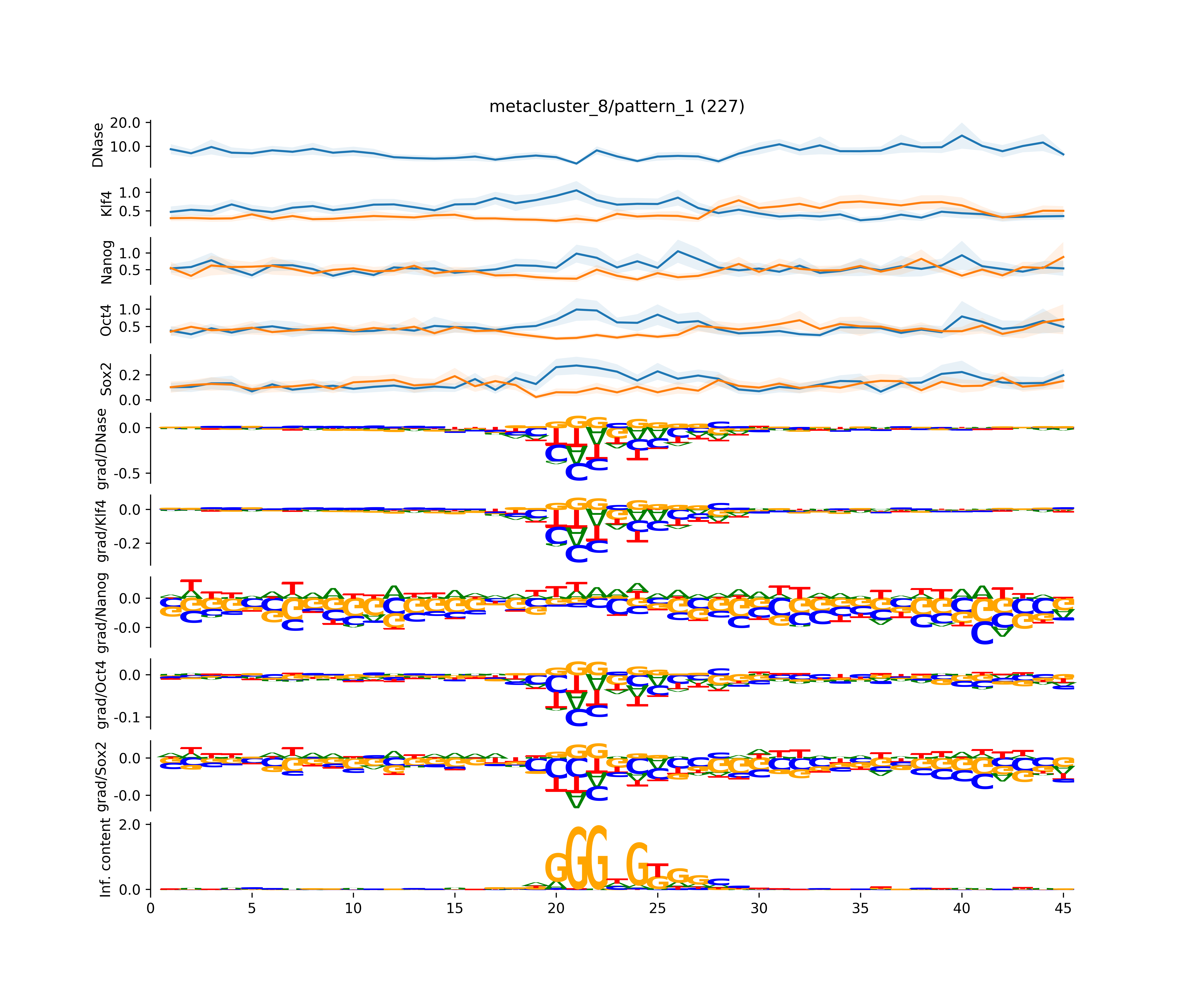
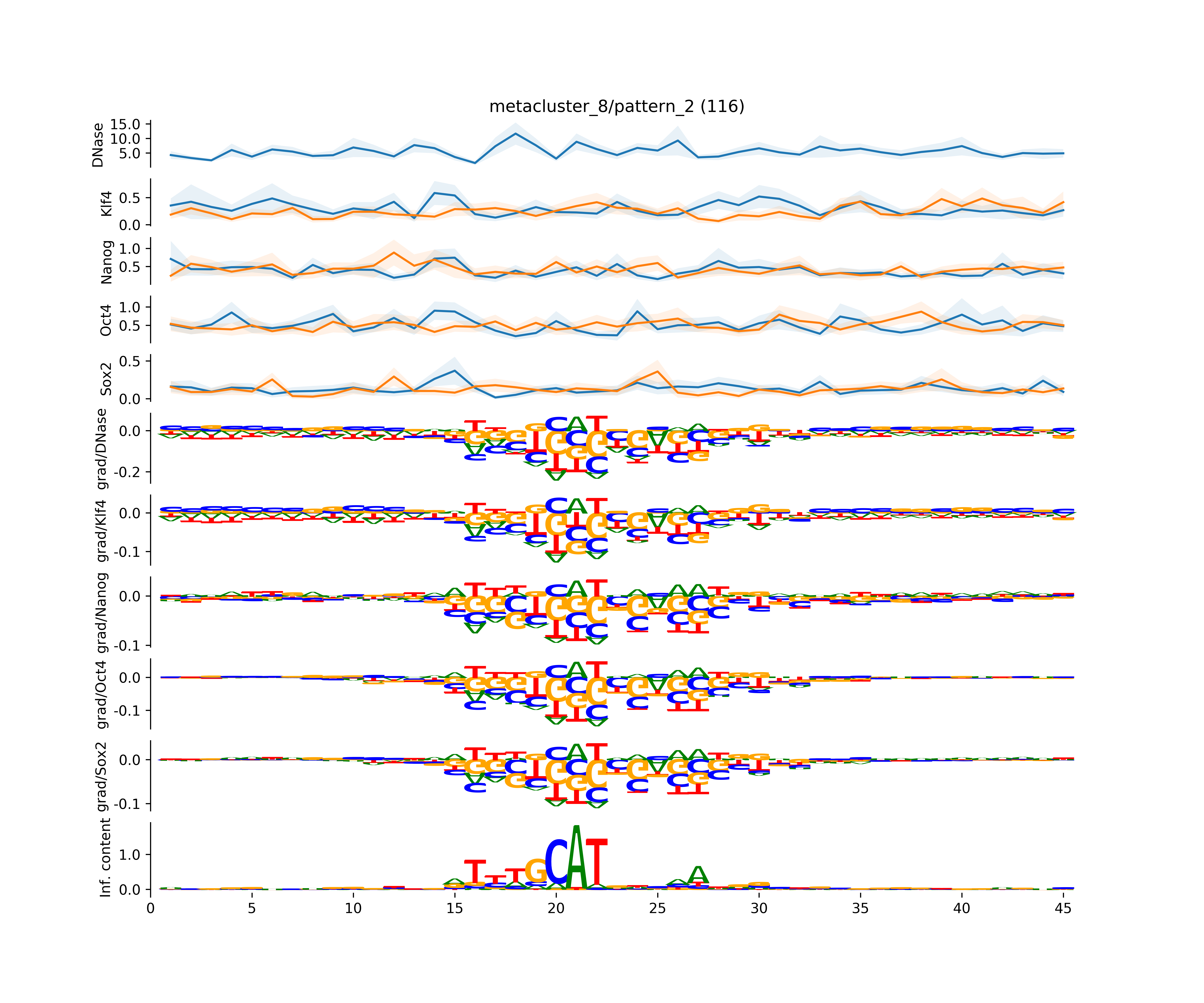
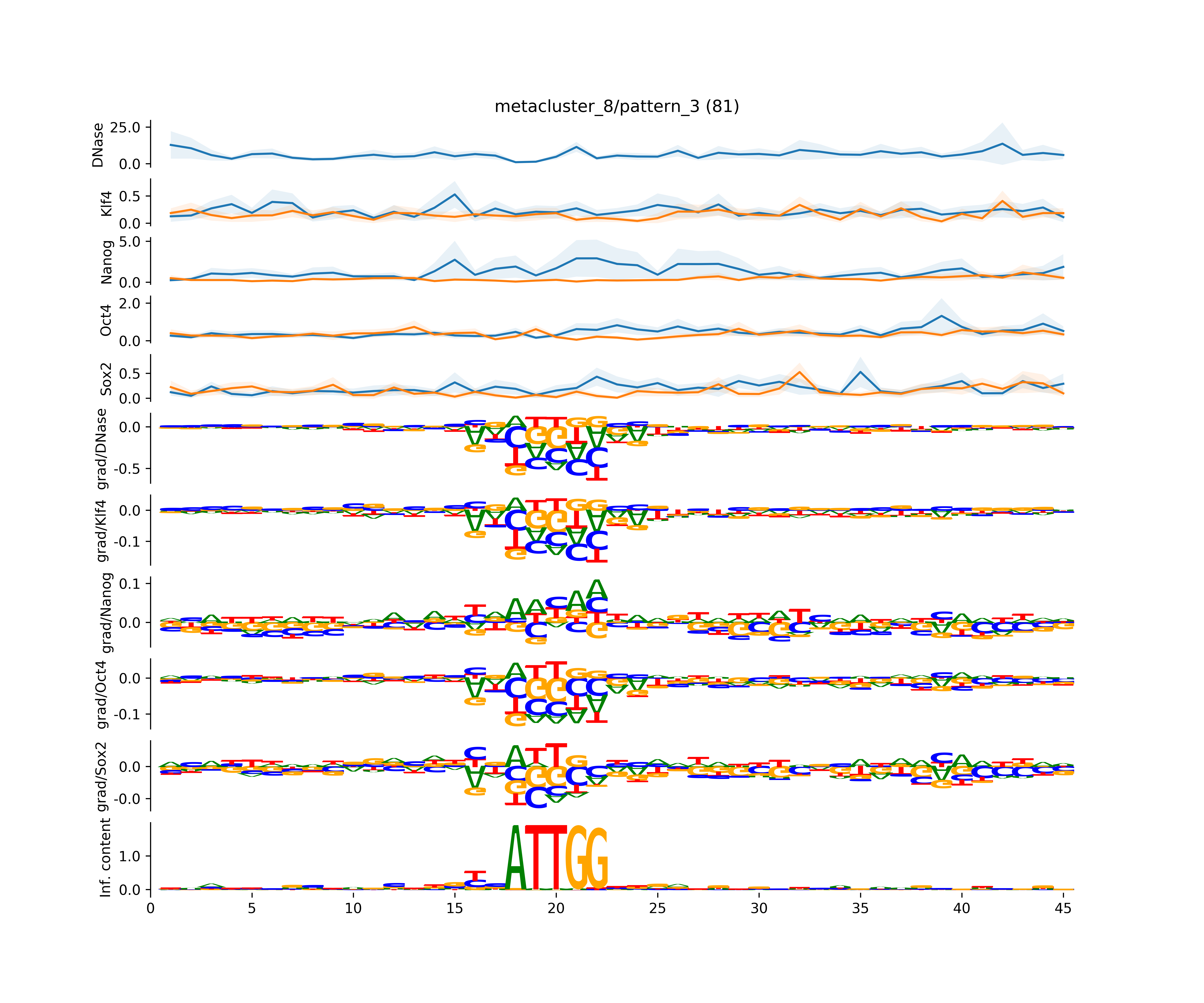
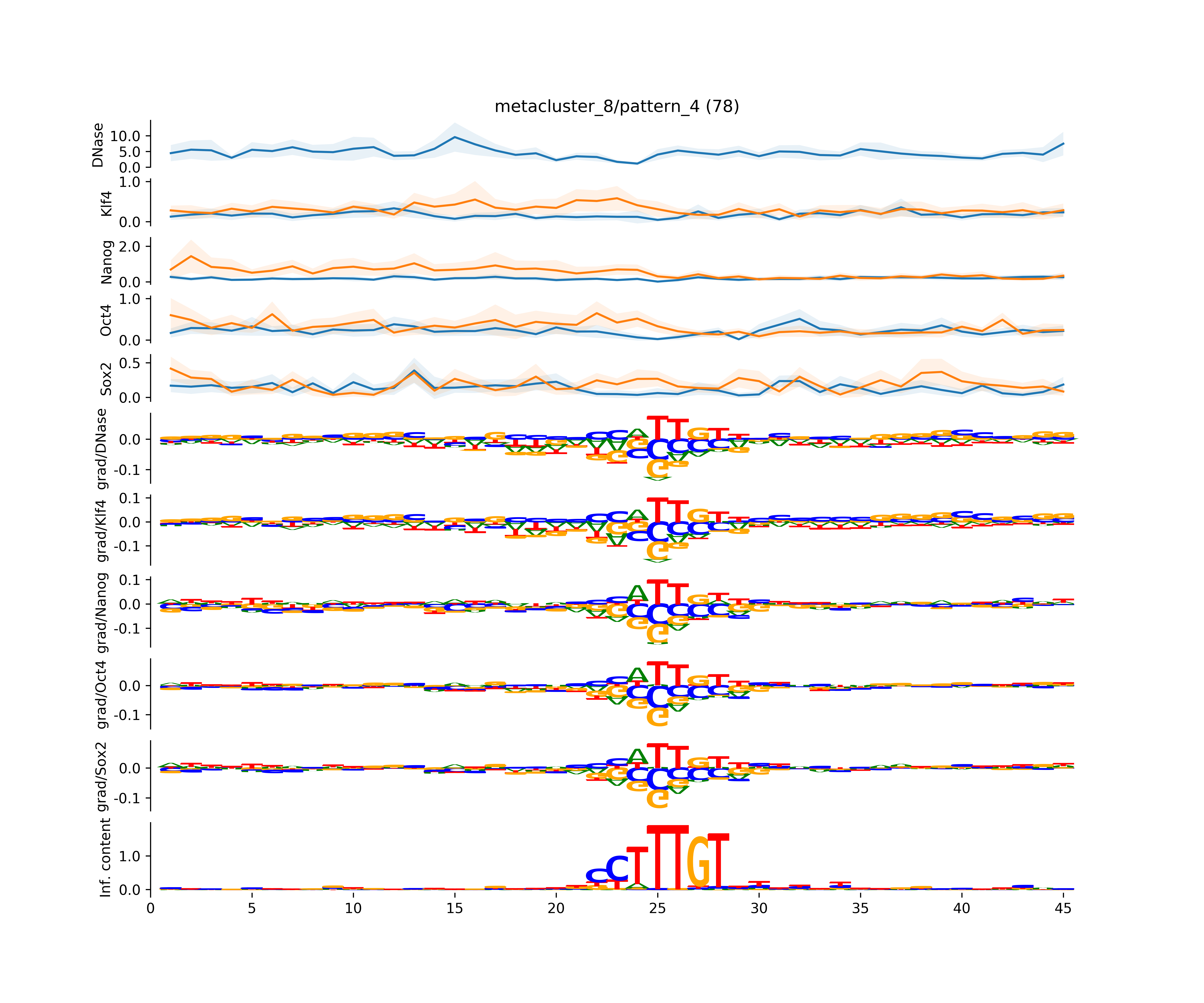
metacluster_8, # patterns: 5, # seqlets: 750, important for: DNase,Klf4,Oct4
pattern_0: # seqlets: 248

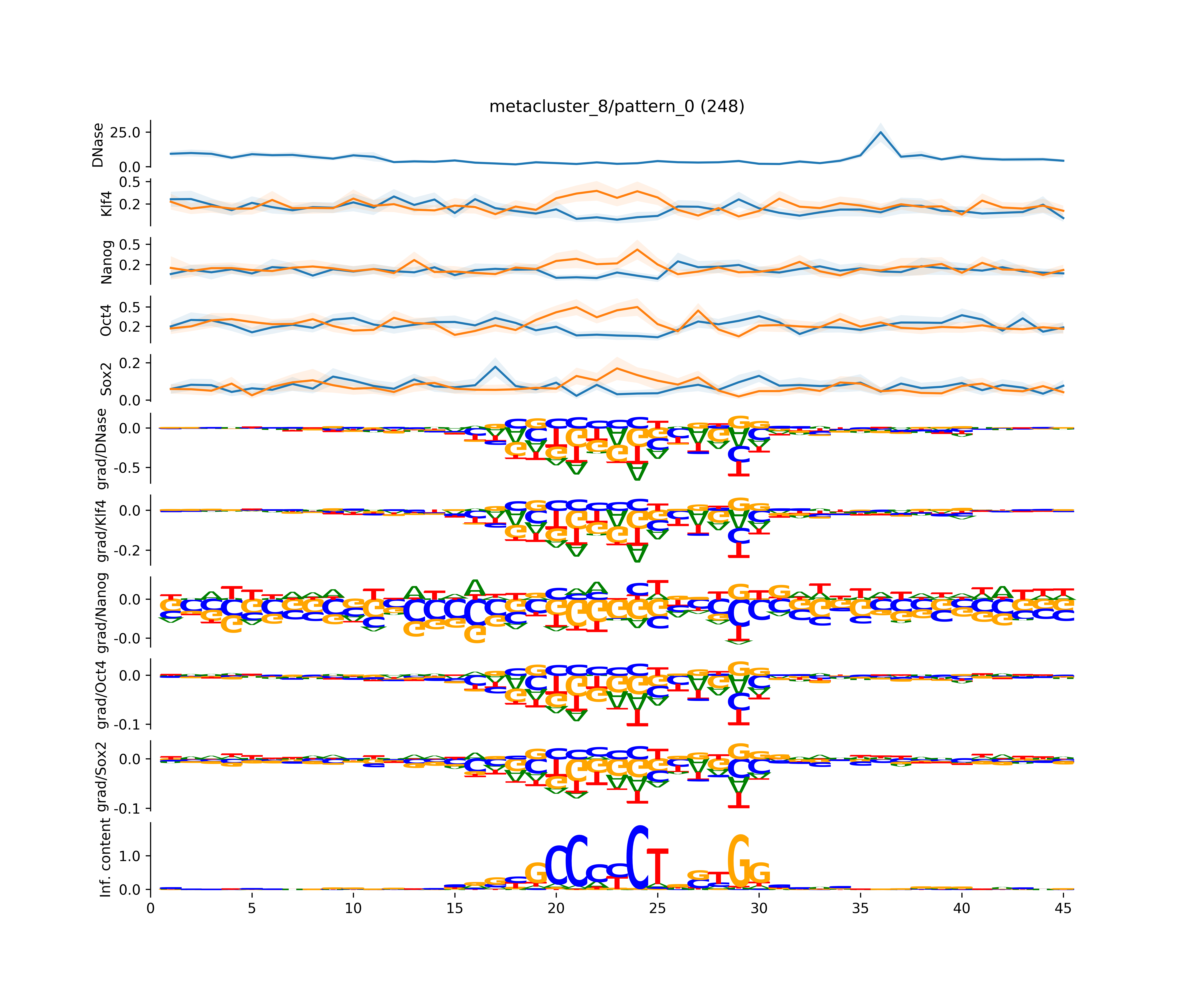
pattern_1: # seqlets: 227

pattern_2: # seqlets: 116

pattern_3: # seqlets: 81

pattern_4: # seqlets: 78

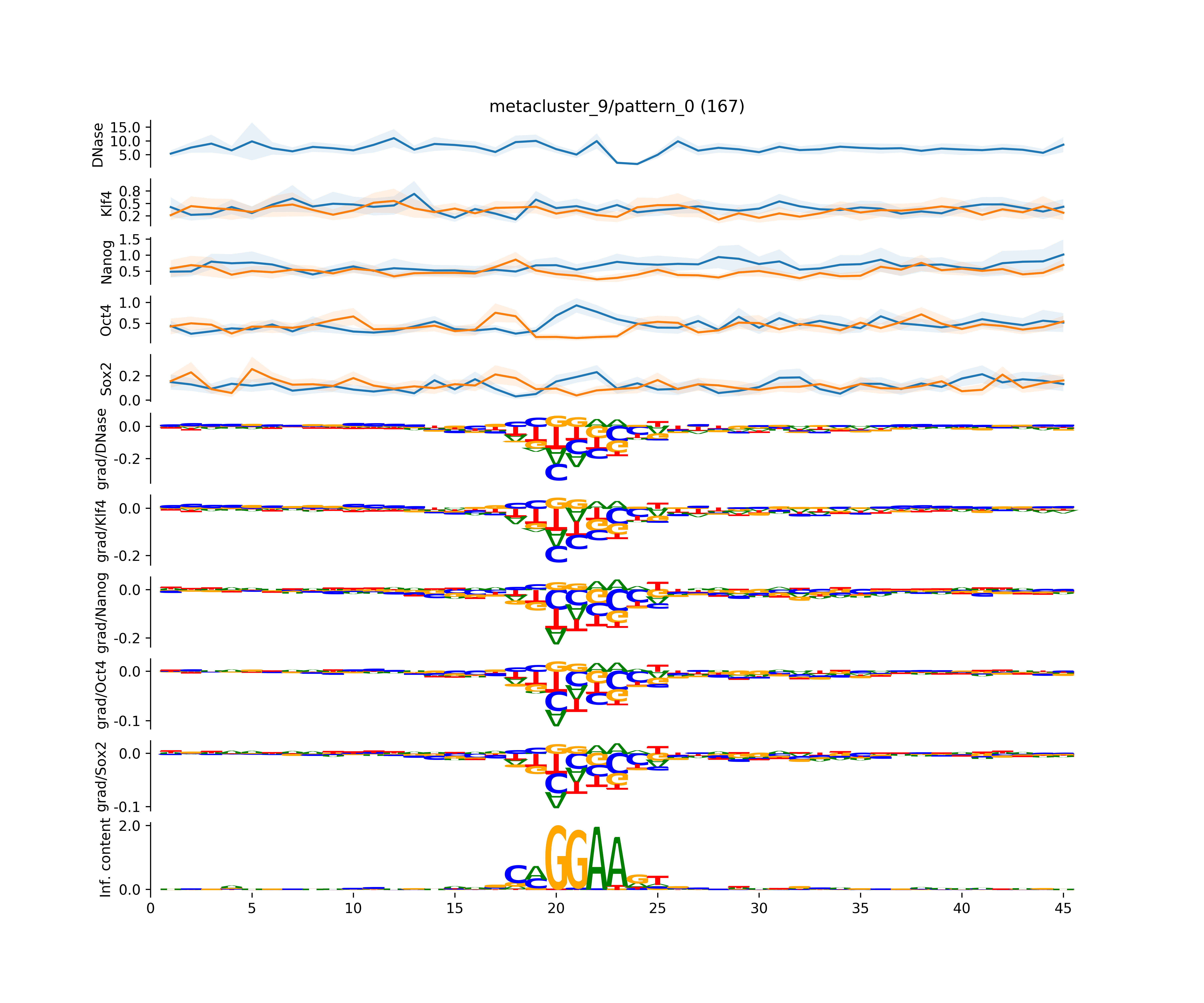
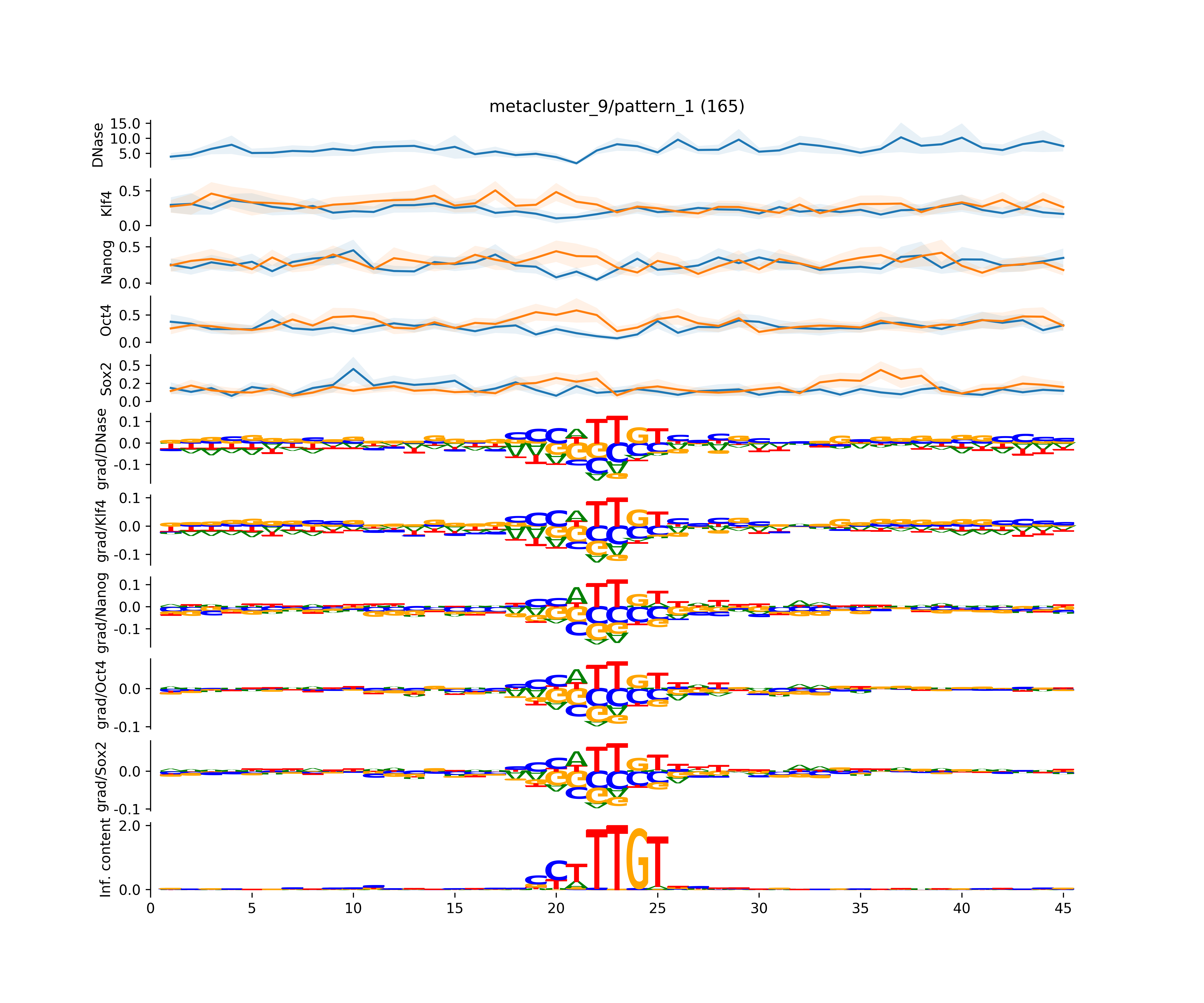
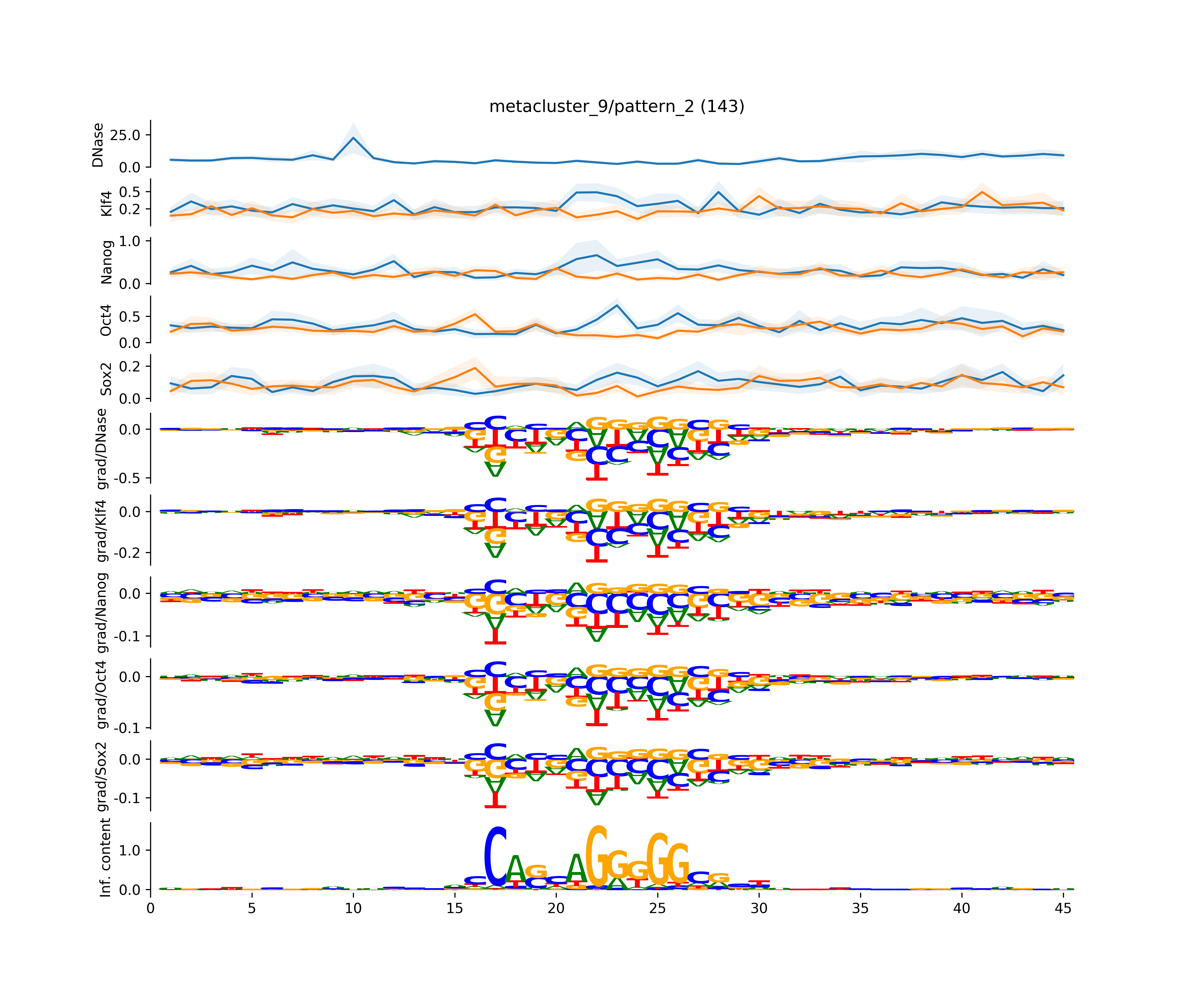
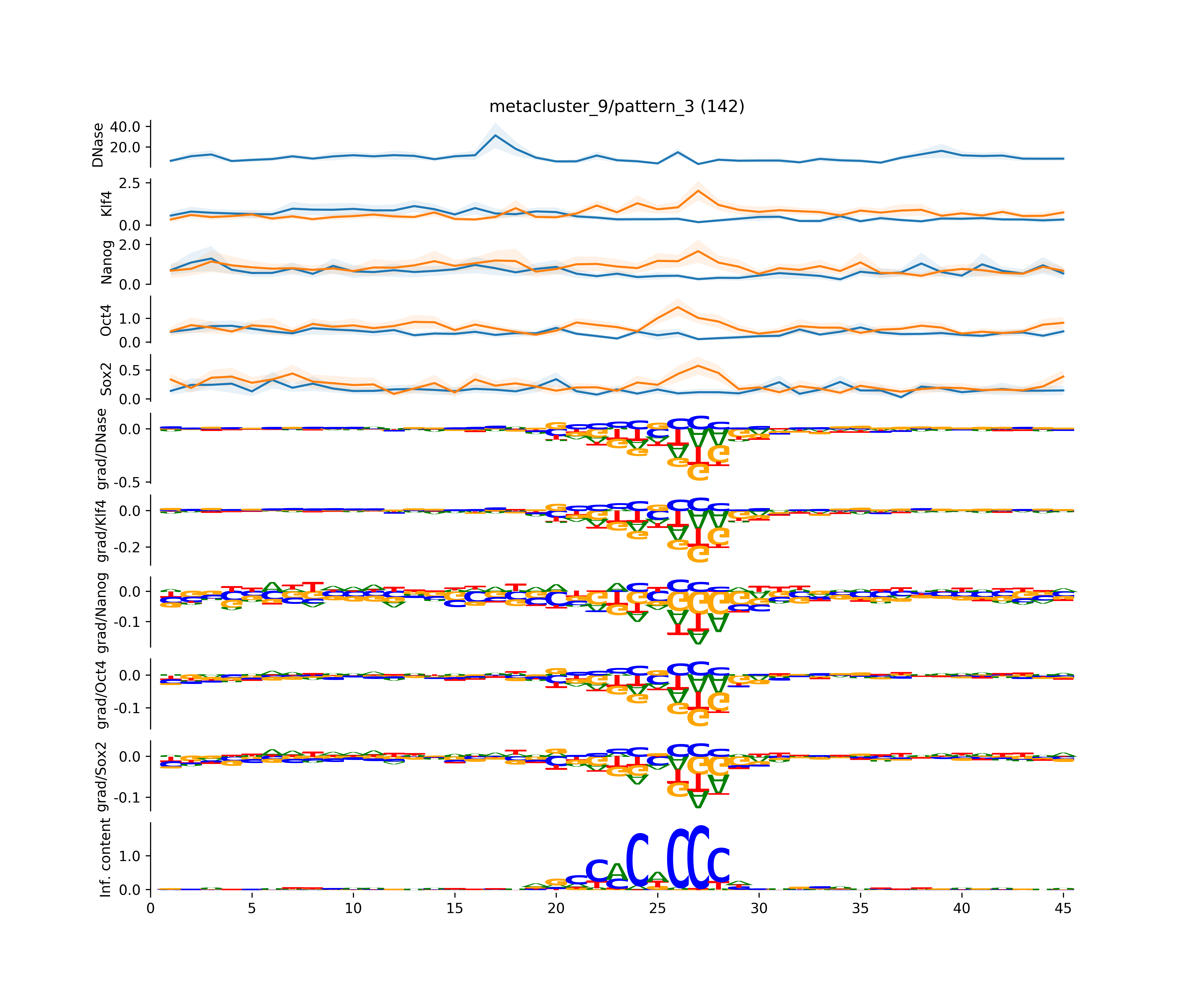
metacluster_9, # patterns: 5, # seqlets: 690, important for: DNase,Klf4,Nanog,Oct4
pattern_0: # seqlets: 167

pattern_1: # seqlets: 165

pattern_2: # seqlets: 143

pattern_3: # seqlets: 142

pattern_4: # seqlets: 73

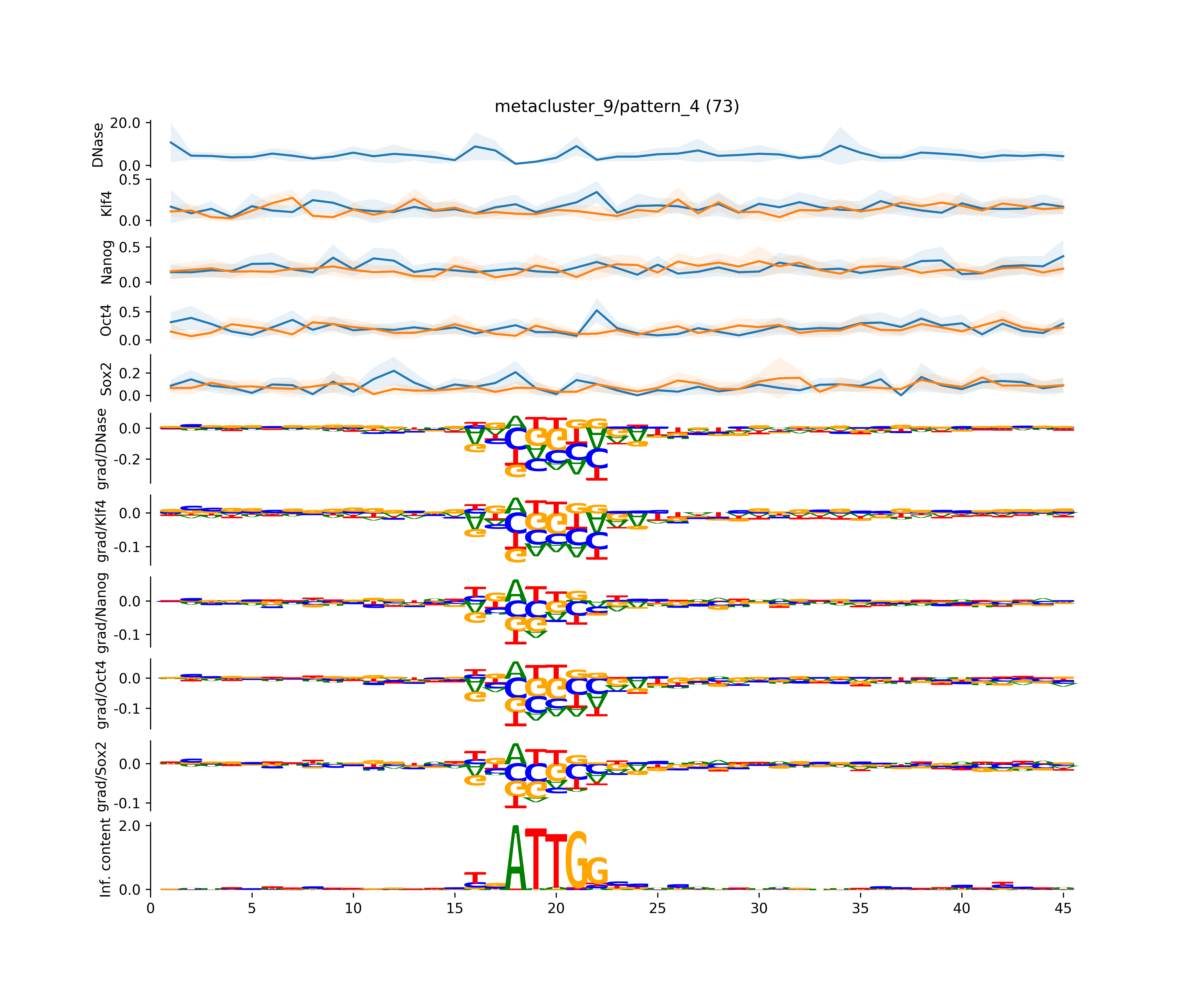
metacluster_10, # patterns: 1, # seqlets: 74, important for: Nanog,Oct4
pattern_0: # seqlets: 74

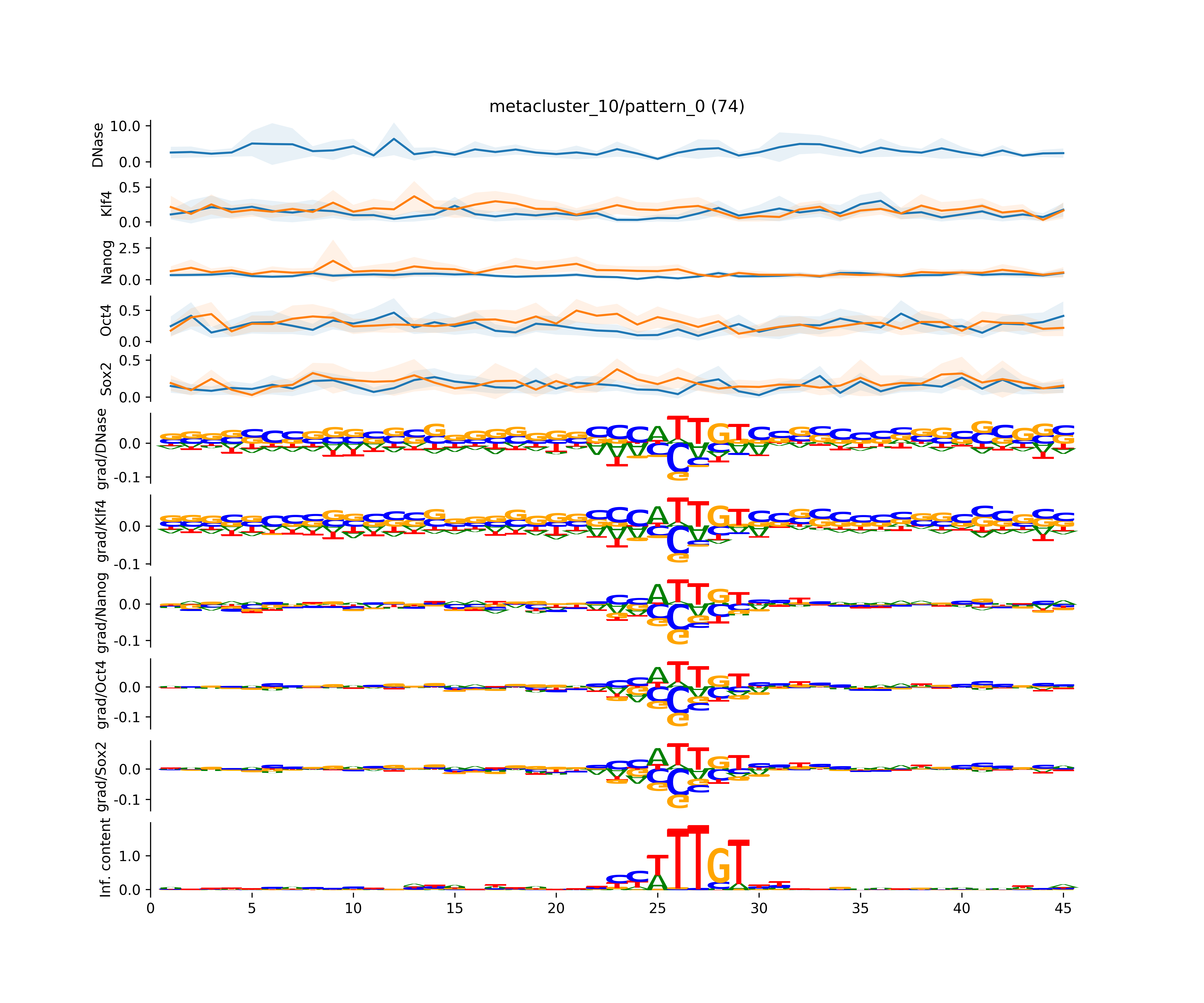
metacluster_12, # patterns: 3, # seqlets: 458, important for: DNase,Klf4,Nanog
pattern_0: # seqlets: 172

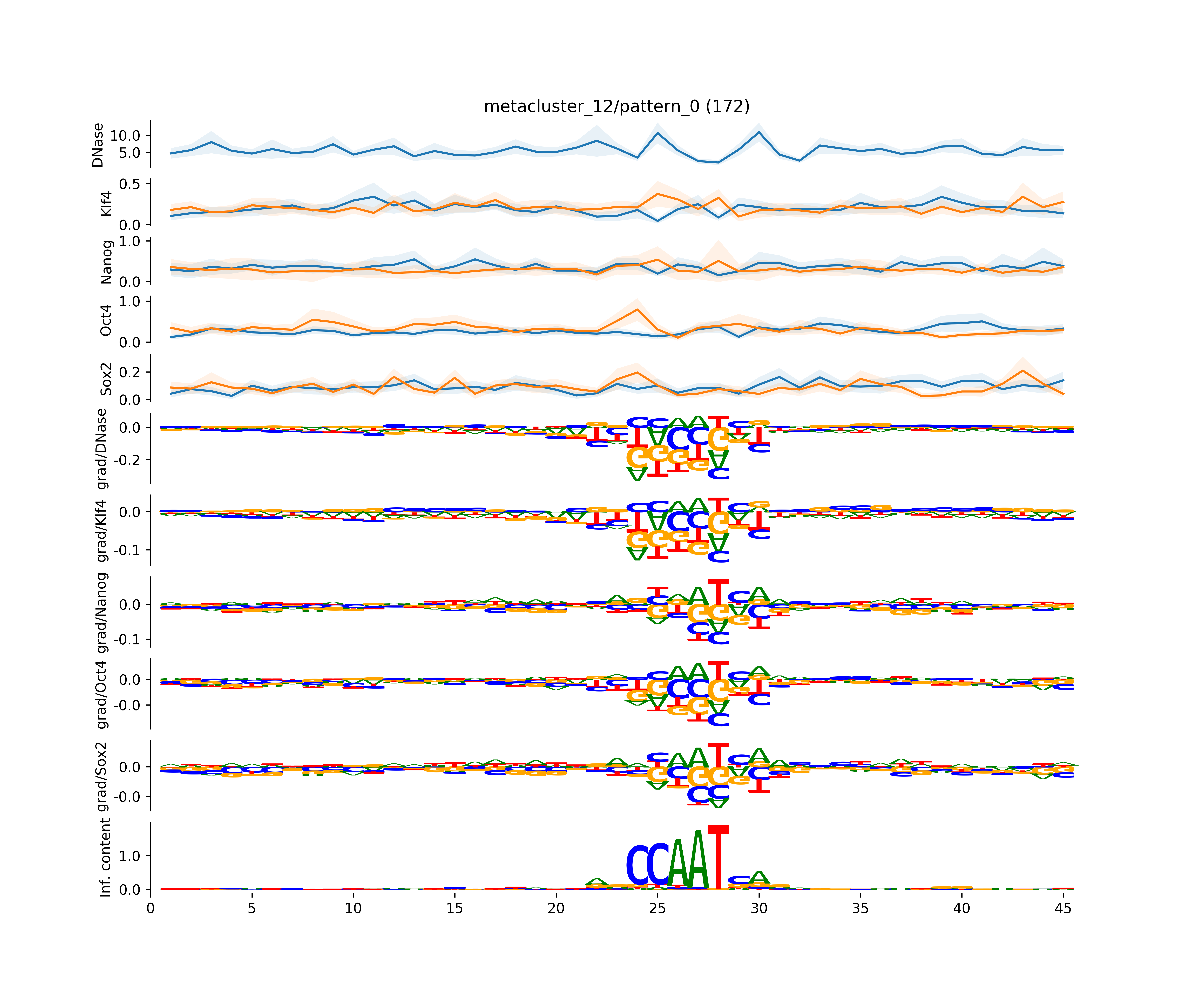
pattern_1: # seqlets: 168

pattern_2: # seqlets: 118

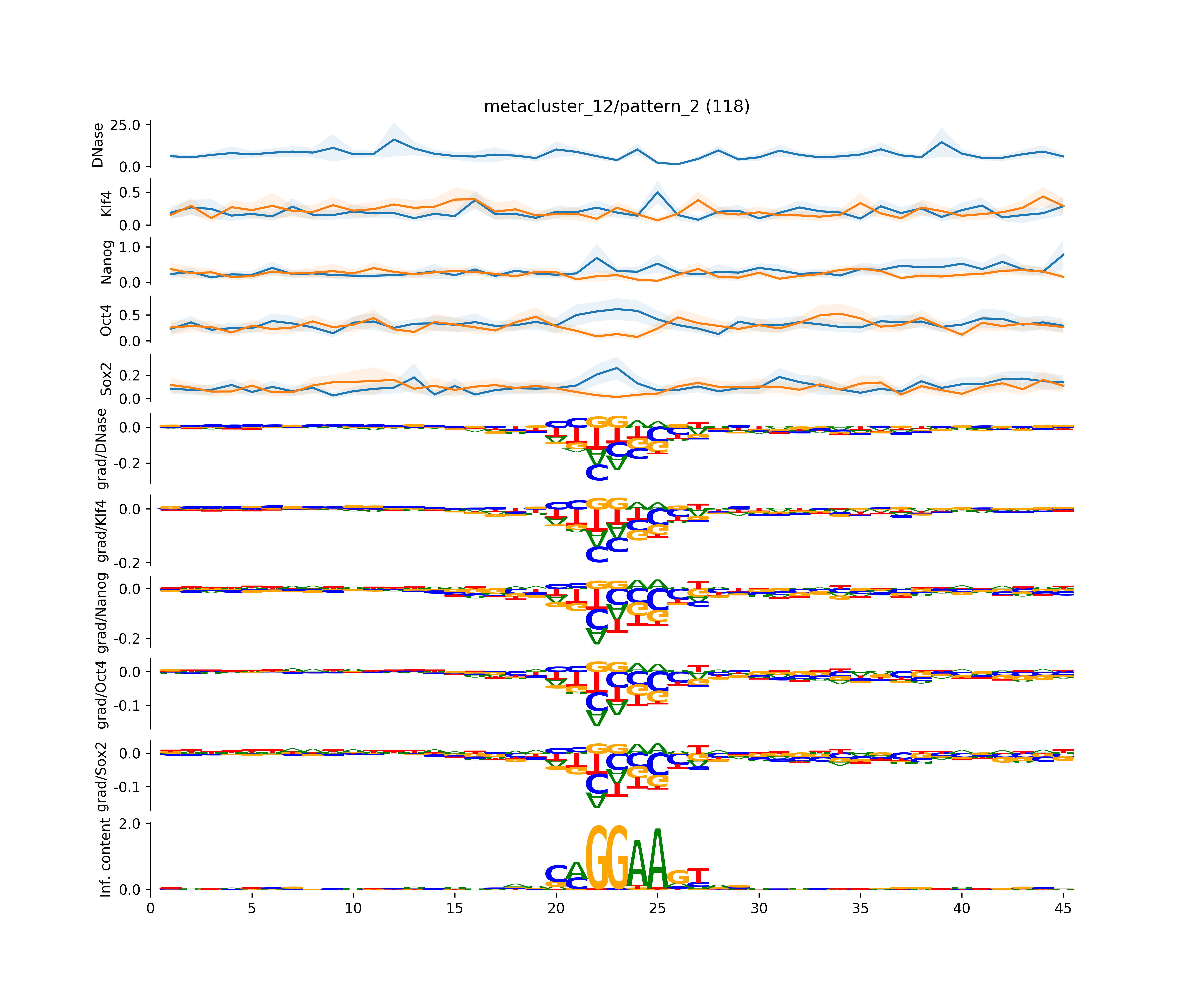
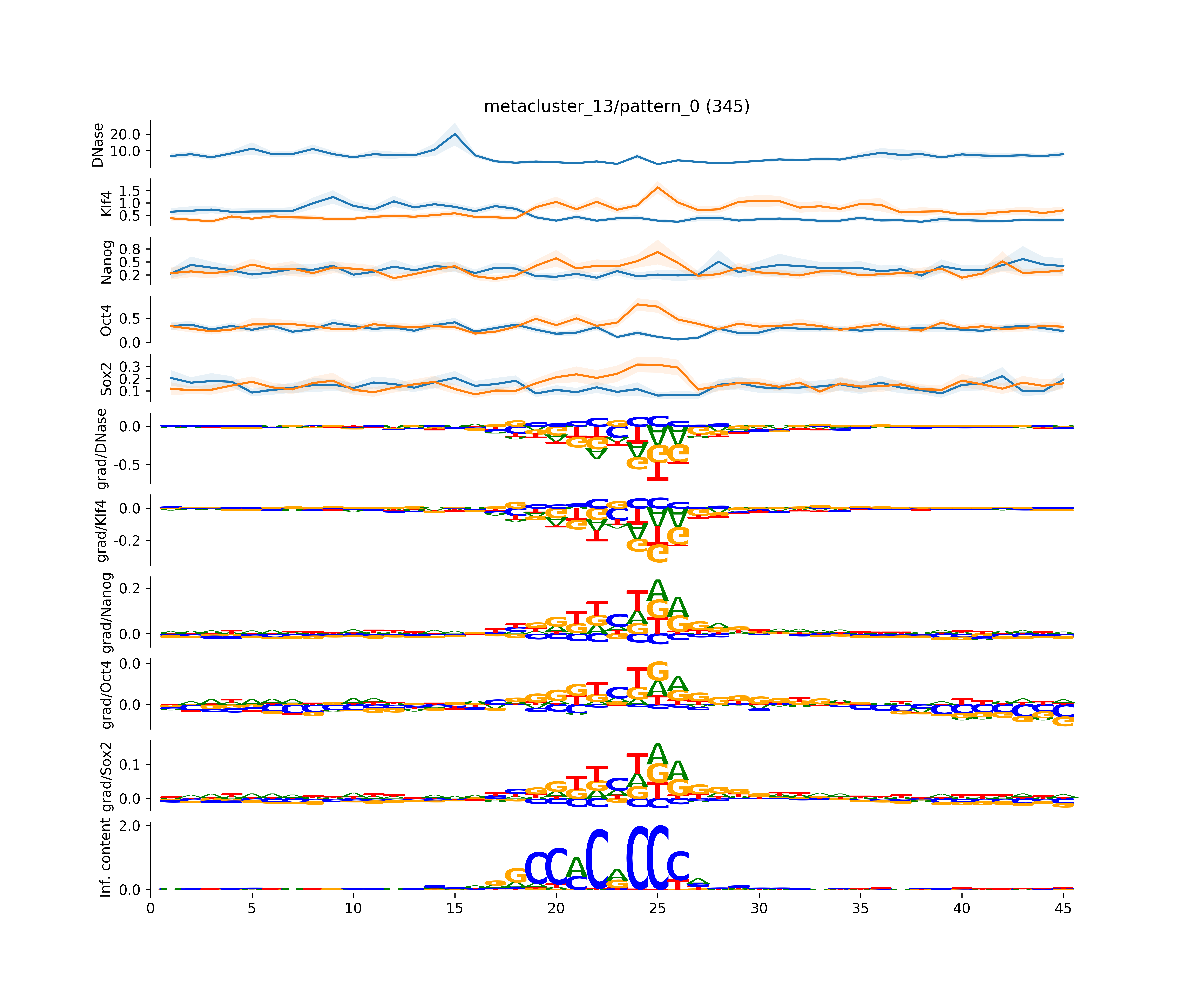
metacluster_13, # patterns: 1, # seqlets: 345, important for: DNase,Klf4,-Nanog
pattern_0: # seqlets: 345

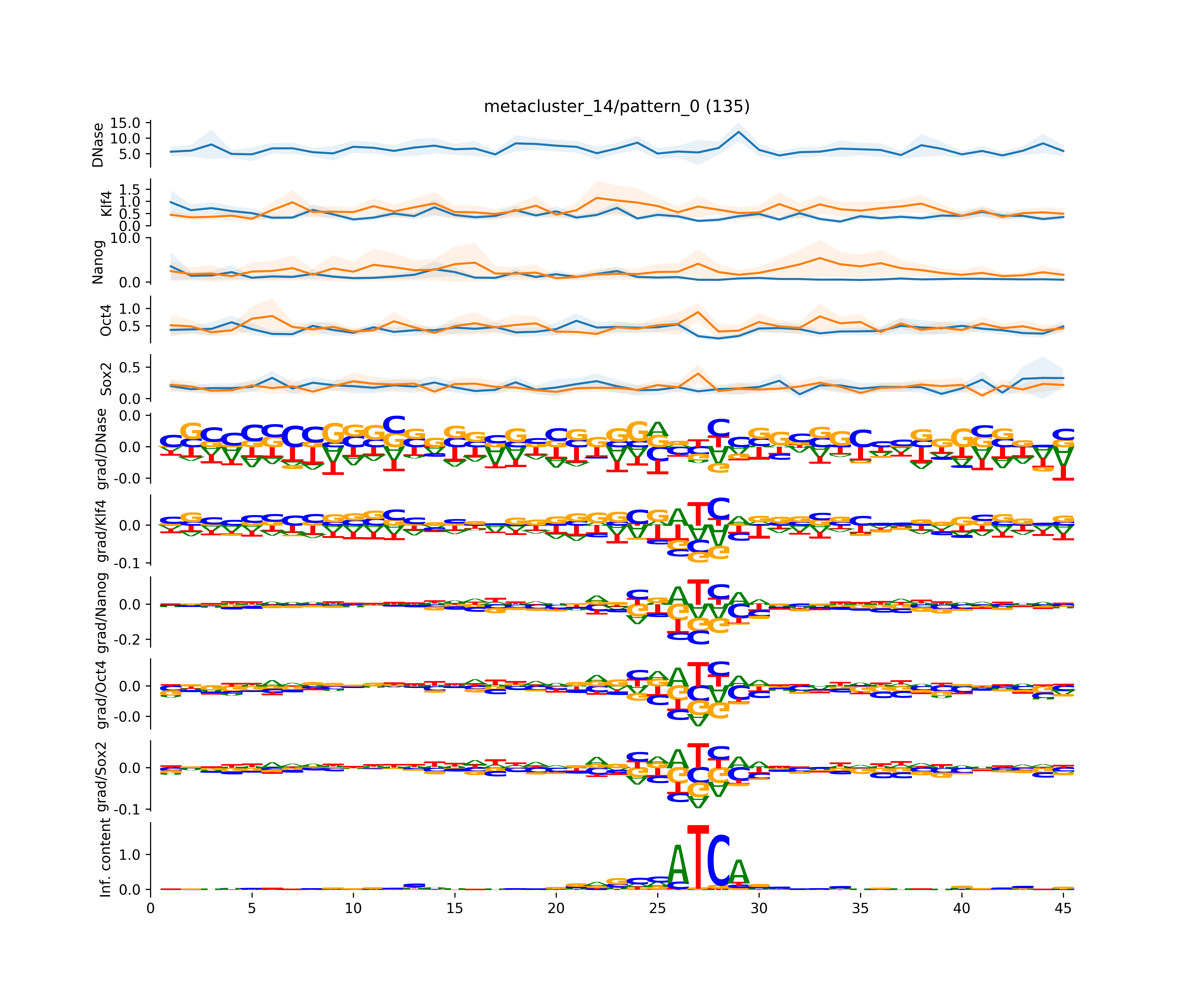
metacluster_14, # patterns: 1, # seqlets: 135, important for: Klf4,Nanog
pattern_0: # seqlets: 135

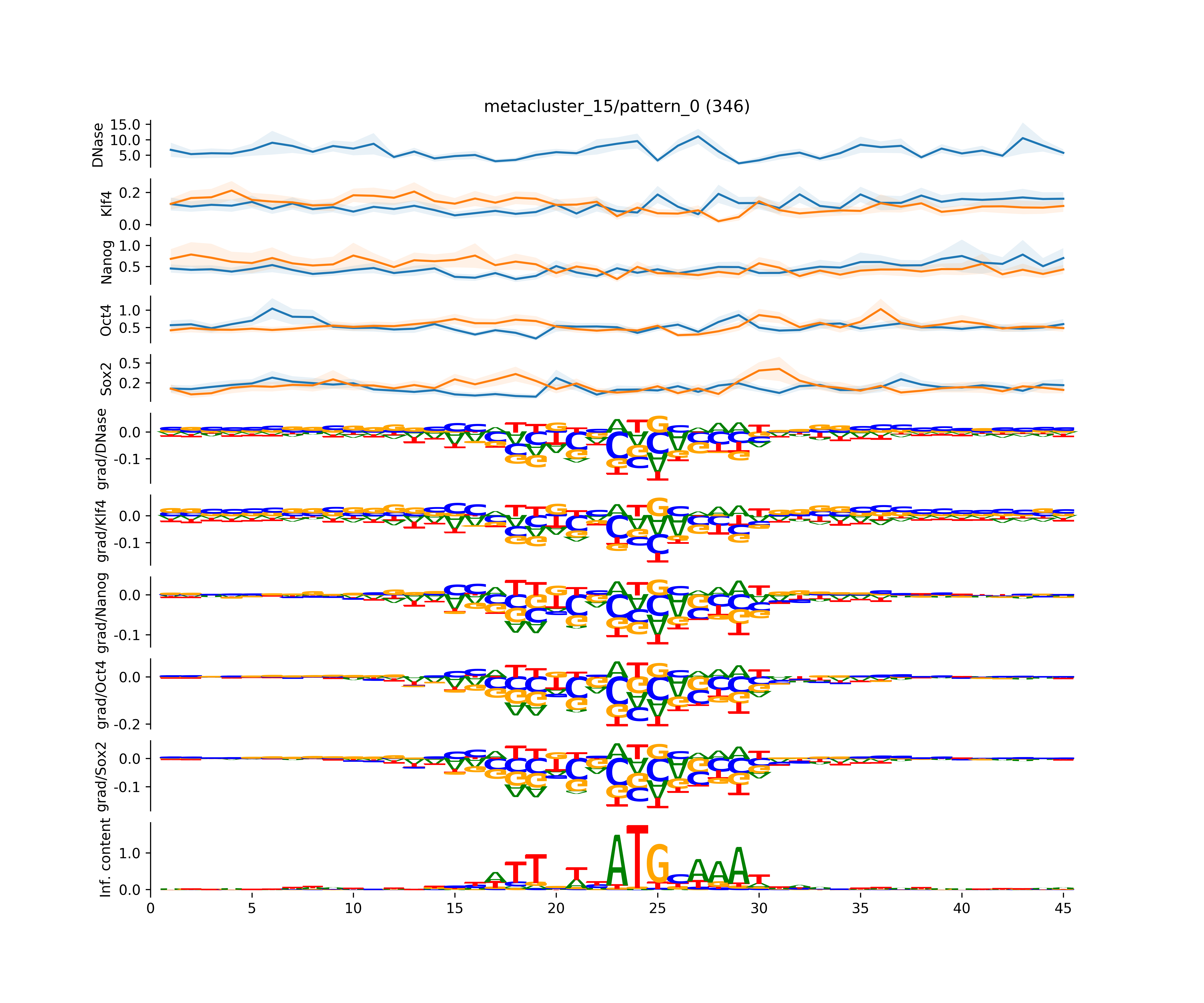
metacluster_15, # patterns: 1, # seqlets: 346, important for: DNase,Nanog,Oct4,Sox2
pattern_0: # seqlets: 346

metacluster_16, # patterns: 1, # seqlets: 150, important for: Nanog,Sox2
pattern_0: # seqlets: 150

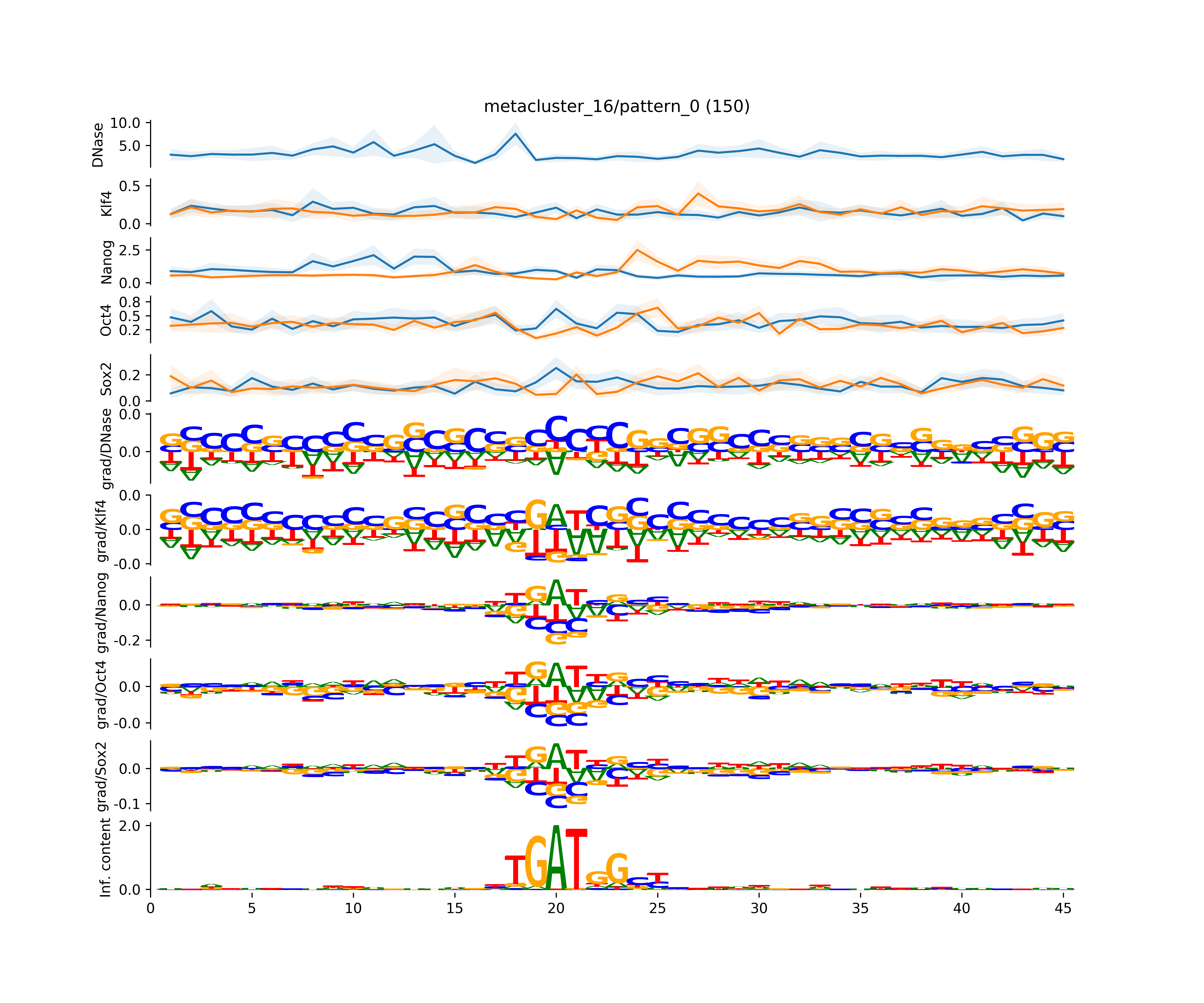
metacluster_18, # patterns: 1, # seqlets: 159, important for: DNase,Klf4,Oct4,Sox2
pattern_0: # seqlets: 159

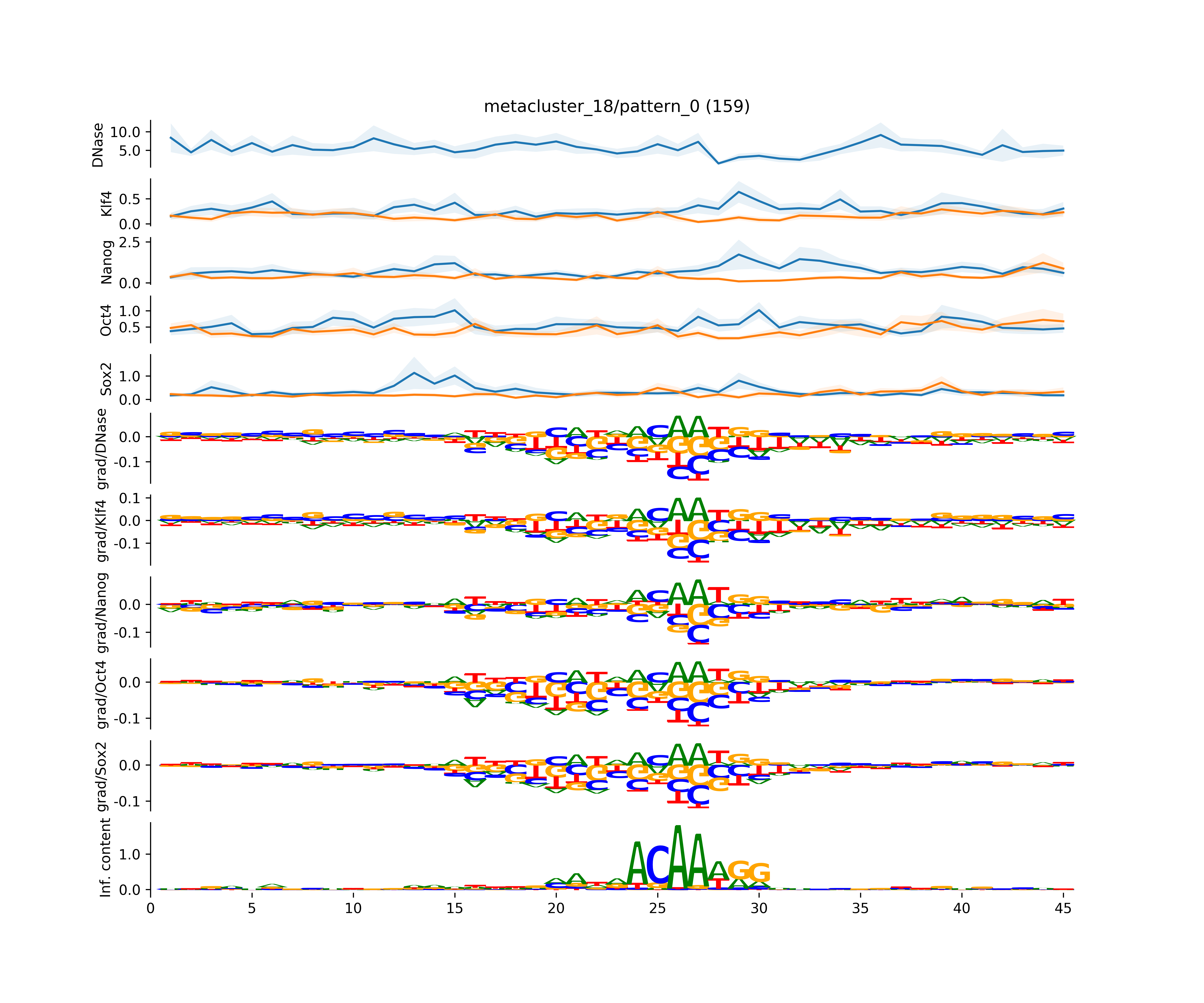
metacluster_24, # patterns: 1, # seqlets: 238, important for: DNase,Oct4,Sox2
pattern_0: # seqlets: 238

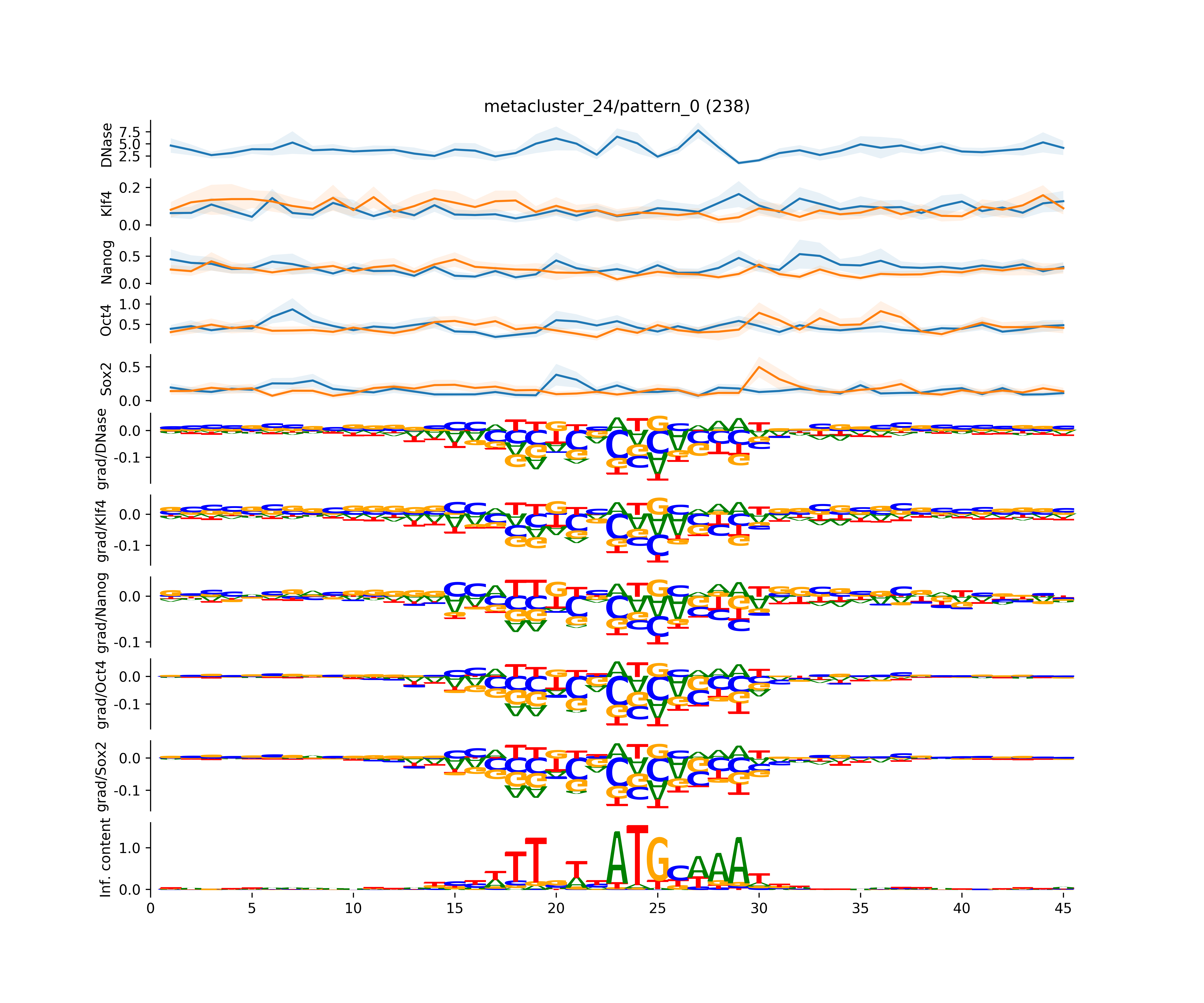
In [12]:
print("Metaclusters heatmap")
import seaborn as sns
activity_patterns = np.array(mr.f.f['metaclustering_results']['attribute_vectors'])[
np.array(
[x[0] for x in sorted(
enumerate(mr.f.f['metaclustering_results']['metacluster_indices']),
key=lambda x: x[1])])]
sns.heatmap(activity_patterns, center=0);
